Scikit-Learn ve Makine Öğrenmesi#
Bu bölümde genellikle makine öğrenmesi kütüphanesi olarak bilinen Scikit-Learn kütüphanesinden bahsedilecektir. Makine öğrenmesi uygulamaları için Pandas, NumPy ve Matplotlib kütüphaneleri birlikte kullanılarak bir model geliştirilebilir. Ancak bu durumda makine öğrenmesi uygulaması için fonksiyonları tekrar tekrar yazmak gereklidir. Scikit-Learn kütüphanesi, makine öğrenmesi süreçlerini içerdiği fonksiyonlar ve matematiksel hesaplamaları sayesinde pratik birtakım yöntemler sunmaktadır. Bu kütüphane veri bilimi süreçlerini kolay bir şekilde yerine getirebilmek için tasarlanmıştır. Bu bölümde öncelikle makine öğrenmesi hakkında teorik bilgi verilecektir. Ardından Scikit-Learn kütüphanesi ile makine öğrenmesi konularına bakılacaktır.
Makine Öğrenmesine Giriş#
Makine öğrenmesi ya da yapay öğrenme geçmiş verilerden faydalanarak gelecekteki verilerin öngörülmesi yani geçmiş verilerden öğrenmesi anlamına gelmektedir. Günümüzde verilerin toplanması ve depolanmasından ziyade veriden bilgi üretme çalışmaları daha değerli bir konuma sahiptir. Yani verinin dönüşümü, yapısal olmayan verilerin yapısal formata getirilmesi, verinin kullanılabilir hale getirilmesi, gizli bilgilerin ortaya çıkarılması çalışmaları ön plana çıkmaktadır. Makine öğrenmesi yapay zekanın uygulama alanlarından birisidir. Makine öğrenmesinin daha spesifik bir alanı ise derin öğrenmedir. Derin öğrenmede görüntü işleme, ses tanıma, akıllı robotlar gibi alanlarda çalışmalar gerçekleştirilir. Makine öğrenmesi uygulamalarında ise genellikle veri setlerinden bilgi çıkarılmaya çalışılır.
Makine öğrenmesi uygulaması için e-postaların spam veya spam olmama olarak iki ayrılması örnek olarak verilebilir. Daha önceden gönderilen ve kullanıcılar tarafından spam olarak işaretlenen veya işaretlenmeyen e-postalardan çıkarım yapılarak yeni e-postalar için bir sınıflandırma yapılabilir. Bu tip çalışmalar sınıflandırma veya gözetimli öğrenme çalışmaları olarak bilinmektedir. Sınıflandırma çalışmalarında geçmişteki verilerin etiketleri ya da hedef değişkeninin değerlerinin bilindiği varsayılır. Hedef değişkenin değerleri bilinmiyor ve tahmin edilmeye çalışılıyorsa bu tip çalışmalar da gözetimsiz öğrenme çalışmaları olarak bilinmektedir.
Makine Öğrenmesinde Temel Kavramlar#
Daha önce veri madenciliğinin kalbinde veri vardır denilmişti. Makine öğrenmesinin en önemli kavramı ise öğrenme tanımıdır. Yapay öğrenmede insanlar ya da hayvanların öğrenme mekanizmaları taklit edilerek makineler üzerinde uygulanmak istenir. Makine öğrenmesindeki esas amaç genelleştirme kabiliyeti olan modeller ortaya koymaktır. Örneğin 100 hastaya ait hastalık verilerinin hastaneye yeni gelecek kişilerde de aynı özelliklerin olması durumunda hasta olup olmadığına bakılabilir. Bu işleme genelleştirme işlemi denilir. Hasta veri seti örneğinde olduğu gibi eğer veri seti çıktı değişkenine sahipse bu öğrenme tipine gözetimli öğrenme denilir. Gözetimli öğrenmede sınıflandırma çalışmaları gerçekleştirilir. Veri setindeki gözlemlerin her biri girdi değişkenlerine(x) ve çıktı değişkenine(y) sahiptir. Dolayısıyla, sınıflandırma çalışmalarında x noktalarıyla y noktası açıklanmaya çalışılır.
Makine öğrenmesi modellerinde ayrıca çıktı değişkenin sayılabilir ya da sayılamaz olması ile de ilgilenilir. Eğer sayılabilir(kantitatif) çıktı değişkeni varsa bu durumda regresyon çalışmaları gerçekleştirilir. Eğer çıktı değişkeni sayılamaz(kalitatif) veri tipinde ise bu durumda sınıflandırma çalışmaları gerçekleştirilir. Regresyon çalışmalarında girdi değişkeni kategorik veya nümerik veri tipinde olabilir. Ancak çıktı değişkeninin nümerik veri tipinde olması gereklidir. Çıktı değişkeninin nümerik olması halinde eğer sınıflandırma çalışması yapılmak istenirse veriler kategorik hale dönüştürülerek işlem yapılabilir. Örneğin çıktı değişkeni 1-60 arasındaki yaşlardan oluşuyorsa 0-20 çocuk, 20-40 genç, 40 ve sonrası orta yaşlı denilerek bir kategorizasyon yapılabilir. Böylece problem sınıflandırma problemi olarak ele alınabilir. Bu bölümde makine öğrenmesi yaklaşımları gösterilecek ve regresyon analizi ile ilgili detaylı inceleme bir sonraki bölümde verilecektir.
Makine öğrenmesi, bir bilgisayar sisteminin veri örnekleri kullanarak kendisini eğitmesi ve belirli bir görevi yerine getirmesi için programlanmasıdır. Bu süreçte kullanılan öğrenme çeşitleri şunlardır:
Gözetimli öğrenme#
Gözetimli Öğrenme (Supervised Learning): Bu öğrenme türünde, önceden belirlenmiş etiketler (labels) ile veriler kullanılarak, bir model oluşturulur. Bu model, daha sonra yeni verileri sınıflandırmak, tahmin etmek veya keşfetmek için kullanılır. Örnek olarak, bir e-postanın spam veya spam olmadığı gibi bir sınıflandırma problemi gözetimli öğrenme örneklerinden biridir.
Sınıflandırma çalışmaları için kullanılacak veri setini oluşturmak veya elde etmek kolay olmaz. Çünkü bazı durumlarda çıktı değişkeninin bilinmesi maliyetli olabilir. Örneğin bir hastalığa ait veri setinde çıktı değişkeni kişinin hasta/hasta değil durumları olsun. Bu durumda hastalık teşhisi gerçekleştikten sonra veri seti oluşabilecektir. Yani veri setindeki her kişi için hastalık teşhisinin yapılmış olması gereklidir. Bu da hastalık teşhisi için zaman ve para maliyetini getirir. Bu nedenle veri setinde çıktı değişkeninin olmaması durumunda da kullanılabilecek modellere ihtiyaç vardır. Bu modeller gözetimsiz öğrenme modelleri olarak bilinir. Gözetimsiz öğrenme modellerinde kullanılan veri setlerine çıktı değişkeni olmadığı için etiketsiz veri setleri de denilebilir. Gözetimsiz öğrenmenin en önemli örneği kümeleme çalışmalarıdır. Kümeleme çalışmalarında, daha önce veriler arasındaki uzaklık ve yakınlık ölçüleri ile veri noktaları arasındaki yakınlıklar ortaya koyularak benzer veriler aynı gruplara atanır. Gözetimsiz öğrenme çalışmaları bir keşif çalışmasıdır. Bu keşif çalışmasında veriler arasındaki ilişkiler, yakınlıklar veya uzaklıklar önemli yer tutar.
Gözetimsiz öğrenme#
Diğer bir öğrenme çeşidi ise yarı gözetimsiz öğrenmedir. Gözetimsiz Öğrenmede (Unsupervised Learning), verilerdeki örüntüleri ve yapıları ortaya çıkarmak için kullanılır. Bu yöntemde verilerin etiketleri veya sınıflandırmaları yoktur. Örnek olarak, bir müşteri veri setinde benzerlik grupları oluşturmak denetimsiz öğrenme örneklerinden biridir.
Gözetimsiz öğrenme algoritmaları, veri kümesindeki örnekler arasındaki benzerlikleri ve farklılıkları belirleyerek veri kümesini önceden belirlenmiş gruplara ayırabilir. Buna kümeleme (clustering) denir. Örneğin, bir müşteri veri kümesi üzerinde yapılan bir kümeleme işlemi, benzer satın alma davranışları sergileyen müşterileri aynı gruba yerleştirebilir.
Gözetimsiz öğrenme ayrıca boyut indirgeme işlemlerinde de kullanılır. Bu işlem, veri kümesindeki öznitelik sayısını azaltarak verilerin işlenmesini kolaylaştırır ve daha az gürültülü sonuçlar elde edilir. Örneğin, bir resim veri kümesindeki yüksek boyutlu öznitelikleri, temel özelliklerine indirgenerek daha az boyutlu bir temsil ile ifade edilebilir.
Gözetimsiz öğrenme, özellikle büyük veri kümelerinde yapısal olmayan desenleri tespit etmek için kullanılır. Ancak, gözetimsiz öğrenme yöntemleri, gözetimli öğrenme yöntemleri kadar kesin sonuçlar veremeyebilir ve elde edilen sonuçların yorumlanması zor olabilir.
Yarı Gözetimli Öğrenme (Semi-Supervised Learning)#
Bu öğrenme türünde, verilerin bir kısmı etiketlenmiş, diğer kısmı ise etiketlenmemiştir. Gözetimli ve denetimsiz öğrenme yaklaşımlarını birleştirir ve bir öğrenme modeli oluşturur. Bu model, etiketlenmemiş verileri sınıflandırmak, tahmin etmek veya keşfetmek için kullanılabilir.
Etiketli veriler, veri kümesindeki örneklerin doğru çıktı bilgilerinin olduğu verilerdir. Bu verilerin kullanılması, gözetimli öğrenme algoritmalarının eğitilmesine olanak tanır. Ancak, etiketli verilerin toplanması genellikle zaman alıcı ve maliyetlidir. Etiketlenmemiş veriler, doğru çıktı bilgilerinin olmadığı verilerdir. Yani, veri kümesindeki örneklerin etiketleri bilinmemektedir. Yarı gözetimli öğrenme, bu verilerin de kullanılmasını sağlar ve veri kümesinin daha iyi işlenmesine olanak tanır.
Yarı gözetimli öğrenme algoritmaları, hem etiketli hem de etiketlenmemiş verileri birleştirerek bir model inşa eder. Etiketlenmemiş verilerin kullanımı, modelin daha iyi özellikler (features) öğrenmesini sağlar ve böylece daha iyi bir performans elde edilir. Bu öğrenme yöntemi, özellikle veri kümesindeki etiketli verilerin sayısının az olduğu durumlarda etkili olabilir.
Yarı gözetimli öğrenme, çeşitli uygulamalarda kullanılır. Örneğin, bir web sitesindeki kullanıcıların davranışlarını takip etmek ve kullanıcıların hangi sayfaları ziyaret ettiğini, hangi ürünleri incelediğini vb. öğrenmek için kullanılabilir. Bu sayede, kullanıcılara daha iyi hizmet sunulabilir ve öneriler yapılabilir. Ayrıca, tıbbi görüntülerde yapısal olmayan desenleri tanımlamak ve kanser tanısında yardımcı olmak gibi diğer uygulamalarda da kullanılabilir.
Pekiştirmeli (Takviyeli) öğrenme#
Pekiştirmeli Öğrenme (Reinforcement Learning) türünde, bir karar verme modeli, verilen bir görev için ödüllendirilir veya cezalandırılır. Bu ödüller veya cezalar, modelin hangi kararları alması gerektiğini öğrenmesine yardımcı olur. Örnek olarak, bir oyun oynayan bir yapay zeka örneği düşünebilirsiniz. Burada, doğru hareketler yaparak oyunu kazanmak için ödüllendirilir, yanlış hareketler ise cezalandırılır.
Bu öğrenme türlerinin her biri farklı bir amaca hizmet etmektedir. Gözetimli öğrenme, sınıflandırma veya regresyon problemlerinde kullanılırken, denetimsiz öğrenme, veri analizi veya kümeleme gibi problemlerde kullanılır. Pekiştirmeli öğrenme, genellikle oyunlar, robotik veya otomatik sürüş gibi algoritmik karar problemleri için kullanılır.
Bu öğrenme yönteminde, model bir ortamda bir dizi eylem gerçekleştirir ve bu eylemler sonucunda bir ödül alır veya ceza alır. Modelin amacı, uzun vadede en yüksek ödülü alacak eylemleri öğrenmektir. Bu süreç, modelin başarılı eylemleri öğrenmesini ve hatalı eylemlerden kaçınmasını sağlar. Örneğin, bir robotun hareketlerini kontrol etmek için pekiştirmeli öğrenme kullanılabilir. Robot, bir ortamda çeşitli eylemler gerçekleştirir (örneğin, ilerler veya döner) ve bu eylemler sonucunda ödül veya ceza alır (örneğin, hedefe yaklaşır veya duvara çarpar). Bu süreç, robotun zamanla en etkili hareketleri öğrenmesini sağlar. Pekiştirmeli öğrenme, öğrencinin herhangi bir önceden tanımlanmış sonuç etiketine bağlı kalmaksızın, doğrudan çevreye yanıt vermesine izin verir. Bu nedenle, pekiştirmeli öğrenme, özellikle robotik, oyunlar, otomatik araçlar ve hatta tıbbi uygulamalar gibi uygulamalar için ideal bir öğrenme yöntemidir.
Eğitim ve Test Setleri#
Gözetimli öğrenmede kullanılan veri seti öğrenmenin gerçekleştirildiği eğitim seti ve öğrenmenin test edildiği test seti olarak ikiye ayrılmaktadır. Birinci set eğitim seti, burada algoritmanın öğrenme gerçekleştireceği veriler bulunur. Sınıflandırmada özellikler ve hedef değişkenlerin olduğu bir settir. Test veri seti ise yine aynı şekilde gözlem değerlerinden oluşur. Ancak bu set eğitime girmez. Onun yerine eğitilen algoritmanın ne kadar iyi çalıştığı ile ilgili kullanılır. Eğitim ve test setleri birbirinden bağımsız olmalıdır. Yani ortak veri içermemelidir. Çünkü ortak veri olması durumunda eğitim setinin ezberlenmesi durumu söz konusu olabilir. Makine öğrenmesinde karşılaşılan önemli problemlerden birisi modelin ezberlemesidir. İngilizcede ezberleme olayına “over-fitting” denilir. Türkçede aşırı öğrenme olarak da isimlendirilebilir. Model eğitim sürecinde ezberler ise performansı yeni gelecek veriler için daha kötü olacaktır. Ezberlemeden kaçınmak için neler yapılacağı ile ilgili detaylı bilgi daha sonra verilecektir.
Bu 2 set dışında ayrıca üçüncü bir setten de bahsedilebilir. O da validasyon veya doğrulama setidir. Bu setin kullanım amacı modelin parametrelerini düzenlemektir. Modelin parametrelerine İngilizcede hyperparameters denilir. Algoritmanın performansı test seti üzerinden değerlendirilir, performans değerlendirmesi doğrulama seti üzerinden yapılmamalıdır. Genel olarak eğitim, test ve doğrulama setlerinin ayrımı için bir oran vermek doğru değildir. Her model için farklılık arz edebilir. Bir oran söylemek şart ise, eğitim seti için %50-60, test seti için %20-30 ve doğrulama seti için %20-30 aralığında veriler kullanılabilir denilebilir.
Çapraz Doğrulama#
Algoritmanın performansının test edilebilmesi için kullanılabilecek bir yöntemdir. Bu yöntemde veri seti belirli sayıda parçaya bölünür. Bölünen parçalardan bir parça test veri seti olarak kullanılır. Diğer parçalar eğitim veri seti olarak kullanılır. Bu sayede tüm parçalar kullanılacak şekilde eğitimin performansı test edilmiş olunur. Parça sayısına İngilizcede “fold” denilir. Yani “10-folds cross validation” 10 parçalı çapraz doğrulama demektir. Aşağıdaki görselde çapraz doğrulamaya ilişkin bir şekil paylaşılmıştır. Görüldüğü gibi eşit parçalara bölünen veri setinde tüm parçalar test amacıyla kullanılacak şekilde bir doğrulama gerçekleştirilmektedir.

Performans Ölçütleri#
Eğitim setinde gerçekleşen öğrenmenin test setinde öğrenme derecesi ile performans ölçütleri hesaplanmaktadır. Ele alınan makine öğrenmesi uygulamasına göre performans ölçütleri farklılık göstermektedir. Örneğin kategorik hedef değişkeninin olduğu sınıflandırma problemlerinde genel olarak kullanılan performans ölçütleri için şu örnekler verilebilir. Karışıklık matrisi sınıfların doğru tahmin edilip edilmediği hakkında bilgi veren bir matristir. Aşağıdaki görselde gösterildiği gibi TP(True Pozitive) doğru tahmin edilen pozitif verilerin sayısını, FP(False Positive) yanlış tahmin edilen negatif sayısını, FN(False Negative) yanlış tahmin edilen negatif değerlerin, TN(True Negative) ise doğru tahmin edilen negatif değerlerin sayısını göstermektedir.

Karışıklık matrisi ile hesaplanacak performans ölçütlerinden ilki doğruluk skorudur. İngilizcede Accuracy Score olarak geçer. Toplam doğru tahminlerin sayısının toplam sayıya bölünerek hesaplanır. En fazla kullanılan performans ölçüsü olmasına rağmen tek başına kullanılması yeterli olmayabilir. Eğer çıktı değerlerinin sayısı birbirinden çok farklı ise doğruluk skoru iyi sonuçlar vermez. Bu durumda kesinlik, duyarlılık ve F1 skoru ölçütlerine bakılabilir. Kesinlik(precision) değerinde pozitif tahmin edilenlerin tüm pozitifler içerisindeki oranı hesaplanır. Kesinlik skoru ile FP yani yanlış tahmin edilen pozitif değerlere dikkat çekilir. Diğer ölçüt ise duyarlılık(recall) performans ölçüsüdür. Bu ölçütte ise yanlış tahmin edilen negatif değerlere dikkat çekilir. İki ölçütün bir arada kullanıldığı F1 skoru ise diğer bir performans ölçüsüdür. Performans ölçütlerinin formülasyonu aşağıda verilmiştir.
Regresyon Analizinde Performans Ölçütleri#
Regresyon analizinde hedef değişkenler sürekli veriler olduğu için karışıklık matrisi kullanılamaz. Regresyon analizinde gerçekleşen ile tahmin edilen arasındaki farka hata terimi denilir. Hata terimi aşağıdaki görseldeki gibi gösterilebilir.

Regresyonda kullanılan performans ölçütlerine aşağıda yer verilmiştir. Ortalama Mutlak Hata(Mean Absolute Error): Tahminlerin gerçek değerlerden mutlak farkının ortalamasıdır. Ortalama Mutlak Hata
MAE=$\(\frac{1}{N}\sum_{i=1}^{N}\left|y_i-\hat{y}\right|\)$
Ortalama Karesel Hata (Mean Squared Error)
MSE=$\(\frac{1}{N}\sum_{i=1}^{N}\left(y_i-\hat{y}\right)^2\)$
Ortalama Karesel Hataların Karekökü ( Root Mean Squared Error)
RMSE=$\(\sqrt{\frac{1}{N}\sum_{i=1}^{N}\left(y_i-\hat{y}\right)^2}\)$
R^2 Skoru (Determinasyon Katsayısı)
Makine Öğrenmesi Projeleri için Uygulanabilecek Adımlar#
Makine öğrenmesindeki temel kavramlardan ve örnek çalışmalardan bahsettikten sonra bir makine öğrenmesi projesi geliştirilirken uygulanabilecek adımlara yer verilebilir.
Makine öğrenmesinin ilk aşamasında problemin ortaya koyulması vardır. Bu aşama bilimsel bir çalışma yapılırken genellikle ilk adım olarak bilinir. Bu aşamada problemin çözümündeki amaçlardan, problemin çerçevesinden, sınırlılıklarından ve kapasitesinden bahsedilebilir. Örneğin spam e-postaların sınıflandırılması probleminde amaç gelen kutusuna gelecek e-postaların filtrelenmesi ve spam e-postaların spam klasörüne gitmesini sağlamaktır. Projenin sınırlılıklarına örnek olarak metin içeren e-postalar ya da 50 kelimenin üzerinde metin içeren e-postalar gibi kısıtlamalar eklenebilir. Bu bilgilerin ortaya koyulması ile problemin tanımlanması aşaması geçilmiş olunur.
İkinci aşamada verilerin elde edilmesi aşaması vardır. Daha önceki bölümlerde verilerin elde edilebileceği ücretli ve ücretsiz kaynaklardan bahsedilmişti. Kimi durumda veri setinin internet kaynaklarından bulunması mümkün olmayabilir. Proje için özel veri seti üretmek, veri toplamak, verileri istenilen formatta kaydetmek bu aşamada yerine getirilmesi gereken işlemlerden olabilir. Diğer aşamada veri setinin istatistiksel yöntemler ile analiz edilmesi aşaması vardır. Proje için belirlenen veya oluşturulan ilk veri seti analize başlamadan önceki haliyle ham veri seti(raw dataset) olarak isimlendirilir. Ham veri setinin analize hazır hale getirilmesi için daha önce bahsedilen veri önişleme süreçlerinin çalıştırılması gerekmektedir. Ardından veri seti içerisinde anlamlı ilişkilerin ortaya çıkarılması için korelasyon gibi ölçütlerin ortaya koyulması gerekebilir. Eğer bir regresyon çalışması yapılacaksa bağımsız değişkenler arasındaki korelasyonun düşük bağımsız değişken ile bağımlı değişken arasındaki korelasyonun ise yüksek olması istenir. Bu çerçevede bir analiz gerçekleştirilerek bazı bağımsız değişkenlerin analizden çıkarılması sağlanabilir. Ayrıca özellikler setindeki hedef değişkenle alakasız olduğu düşünülen değişkenler de sistemden çıkarılmalıdır. Spam e-posta örneğinde e-postaları gönderen kişilerin cinsiyetine bakmak gereksizdir. Cinsiyet özelliğinin veri setinden ve özellikler kümesinden çıkarılması başta düşünülmesi gereken bir süreç olmalıdır. Bunun gibi varsa başka alakasız özellikler bunların tespit edilerek analizden çıkarılması öğrenmenin kalitesine olumlu yönde etki edecektir. Bu aşamada özellik çıkarımı, özellik mühendisliği gibi yöntemlerden faydalanılmalıdır. Özellikler setine karar verildikten sonra ise veri setinin eğitim ve test seti ya da gerekli görülürse doğrulama veri seti olarak ayrılması işlemine geçilebilir.
Sonraki aşamada makine öğrenmesi algoritmasının ortaya koyulması var. Modelin seçilmesi ile modelin diğer modeller ile kıyaslanması, modelin performans değerlendirmesi gibi süreçler bu aşamada yerine getirilir.
Modeldeki parametrelerin ayarlanması, optimizasyonu süreçleri, modelin seçilmesinden sonra gerçekleştirilecek aşamadır. Bu aşamada parametre optimizasyonu veya hiperparametrelerin belirlenmesi işlemleri için literatürde geliştirilmiş yöntemlerden faydalanılabilir. Bu yöntemlere örnek olarak “Grid Search” verilebilir. Bu yöntem dışında çeşitli optimizasyon algoritmaları da kullanılabilir. Optimizasyon algoritmaları problemin karmaşıklığına göre sezgisel veya deterministik yöntemler olabilir.
Son aşamada ise projenin raporlanması ve sonuçlarının uygun şekilde sunulması işlemleri vardır. Bu aşamada gerekli istatistiksel testler, çapraz doğrulama sonuçları, sonuçların geçerlilik testleri gibi analizlerin verilmesi gerekir.
Yukarıda verilen aşamalar ayrıca şekilde özetlenmiştir. Makine öğrenmesi projeleri için bu aşamalar yerine getirilebilir. Tabii bu aşamalar şart olarak söylenemez. Bu aşamalar projeden projeye değişiklik gösterebilir.

Doğru makine öğrenmesi algoritmasının seçilmesi#
Makine öğrenmesi algoritmalarını seçerken dikkat edilmesi gereken bazı faktörler vardır:
Veri türü: Verilerin türü, hangi makine öğrenmesi algoritması seçileceği konusunda önemli bir rol oynar. Sınıflandırma, regresyon veya kümeleme gibi farklı problemler için farklı algoritmalar mevcuttur.
Veri boyutu: Veri boyutu, hangi algoritmanın seçileceğini belirler. Büyük veri kümeleri için farklı algoritmalar kullanılabilirken, küçük veri kümeleri için farklı algoritmalar daha etkilidir.
Hız ve performans: Algoritmaların hızı ve performansı, belirli bir veri kümesinde nasıl çalışacağına dair bir fikir verir. Büyük veri kümeleri için daha hızlı algoritmalar tercih edilir.
Eğitim verileri: Hangi algoritmanın seçileceği, eğitim verilerinin doğru bir şekilde anlaşılmasıyla da ilgilidir. Eğitim verileri, algoritmanın öğrenme sürecini etkiler ve bu nedenle doğru bir şekilde analiz edilmelidir.
Doğruluk ve sonuçların yorumlanması: Makine öğrenmesi sonuçları doğru bir şekilde yorumlanmalıdır. Farklı algoritmaların doğruluğu farklı olabilir ve sonuçların ne anlama geldiği doğru bir şekilde anlaşılmalıdır.
Ölçeklenebilirlik: Algoritmanın ölçeklenebilir olması, daha büyük veri kümeleriyle çalışmak isteyenler için önemlidir.
Parametreler: Makine öğrenmesi algoritmaları, bir dizi parametre ile yapılandırılabilir. Hangi parametrelerin seçileceği, doğru sonuçların elde edilmesi için önemlidir.
Bu faktörlerin dikkate alınması, doğru makine öğrenmesi algoritmasının seçilmesine yardımcı olabilir. Ancak, bu seçim, deneyimli bir veri bilimcisi veya makine öğrenmesi uzmanı tarafından yapılmalıdır. Aşağıdaki görselde bir yol haritası gösterilmiştir. Ayrıca bu alanda yazılmış olan şu makale de önemli bir izlenim sunacaktır.

Başarısızlık Nedenleri#
Makine öğrenmesi çalışmaları birçok denemeyi, deneme ve yanılmayı, tekrarlı çalışmaları, stresli işlemleri kapsayan zor bir iştir. Genel anlamda makine öğrenmesinin zorlukları veri setinden kaynaklı veya seçilen modelden kaynaklı olabilir. Veri setinin doğru seçilmemesi, eksik, hatalı, yanlış veriler içermesi gibi sorunlar makine öğrenmesi çalışmasını da zora sokabilir. Aynı şekilde veri seti doğru şekilde elde edilse de ardından uygulanan modelle ilgili sorunlar ortaya çıkabilir. Makine öğrenmesinde karşılaşılan zorluklar şu şekilde verilebilir.
Yeterli verinin olmaması
Verilerin kaliteli olmaması
Doğru algoritmanın seçilmemesi
Problemin makine öğrenmesi ile çözülmesinin mantıklı olmaması
Aşırı öğrenme(Overfitting)
Az Öğrenme (Underfitting)
Scikit-Learn Kütüphanesi Hakkında#
Scikit-Learn kütüphanesine geçmeden önce Scikit-Learn ile kullanılan diğer kütüphaneler hakkında aşağıdaki bilgiler verilebilir. Verilen kütüphaneler, bilimsel çalışmalarda sıklıkla kullanıldığı için SciKits (Science Kits – Bilim Araçları) olarak bilinmektedir. SciKits kütüphaneleri aşağıdaki gibi listelenebilir.
NumPy: N-Boyutlu diziler ve hesaplama kolaylığı sağlayan fonksiyonları sayesinde önemli avantajlar sunmaktadır.
Pandas: Seriler ve veri çerçeveleri veri yapıları ile tablo formatındaki verilerin manipülasyonu ve analizi için önemli avantajlar sunmaktadır.
Matplotlib: Verilerin görselleştirilmesi için kullanılmaktadır.
SciPy: Bilimsel hesaplamalar için kullanılan Python kütüphanesidir.
Scikit-Learn kütüphanesi açık kaynak kodlu bir Python kütüphanesidir. İlk olarak 2007 yılında Google Summer of Code etkinliğinde David Cournapeau tarafından geliştirilmiştir. Şu anda Google, the Python Software Foundation ve INRIA tarafından desteklenen 30’a yakın çalışanı ile geliştirilmesi devam etmektedir. Temel olarak NumPy ve SciPy kütüphaneleri üzerine kurulmuştur. Kütüphanenin ana sayfası http://scikit-learn.org/ adresinde bulunmaktadır.
Ana sayfada verildiği gibi Scikit-Learn kütüphanesi şu şekilde tanımlanabilir.
Tahmine dayalı veri analizi için basit ve verimli araçlar
Herkes tarafından erişilebilir ve çeşitli bağlamlarda yeniden kullanılabilir.
NumPy, SciPy ve Matplotlib üzerine inşa edilmiştir.
Açık kaynak kodlu, ticari olarak kullanılabilir - BSD lisansına sahip. Yine kendi sayfasından Scikit-Learn kütüphanesinin çalıştığı alanlar şu şekilde özetlenebilir.
Uygulama Alanı |
Tanım |
Uygulamalar |
Algoritmalar |
|---|---|---|---|
Sınıflandırma |
Nesnenin hangi kategoriye ait olduğunu belirleme. |
İstenmeyen posta algılama, görüntü tanıma. |
en yakın komşular, rastgele orman ve daha fazlası… |
Regresyon |
Bir nesneyle ilişkili sürekli değerli bir özniteliği tahmin etme. |
İlaç tepkisi, hisse senedi fiyatları. |
en yakın komşular, rastgele orman ve daha fazlası… |
Kümeleme |
Benzer nesnelerin kümeler halinde otomatik gruplandırması. |
Müşteri segmentasyonu, Gruplandırma deneme sonuçları |
k-Means, spectral clustering, mean-shift, |
Boyut Azaltma |
Dikkate alınması gereken rastgele değişkenlerin sayısını azaltma. |
Görselleştirme, Artan verimlilik |
k-Means, feature selection, non-negative matrix factorization |
Model Seçme |
Parametreleri ve modelleri karşılaştırma, doğrulama ve seçme. |
Parametre ayarlama ile geliştirilmiş doğruluk |
grid search, çapraz doğrulama, metrikler |
Veri Önişleme |
Özellik ayıklama ve normalleştirme. |
Metin gibi giriş verilerini makine öğrenimi algoritmalarıyla kullanmak üzere dönüştürme. |
önişleme, özellik çıkarımı |
Scikit-Learn kütüphanesinin öne çıkmasının en önemli nedenlerinden birisi de iyi belgelendirilmiş olmasıdır. Makine öğrenmesi metotları kimi zaman karmaşık matematiksel ifadeler içerebilir. Scikit-Learn olabildiğince basit bir şekilde makine öğrenmesi metotlarını sunmaktadır. Böylece ileri düzey bir matematiğe ihtiyaç duymadan da makine öğrenmesi uygulaması geliştirmek mümkün olabilmektedir.
Bu özellikleri sayesinde Scikit-Learn birçok önemli işletme tarafından kullanılmaktadır. Örneğin Spotify, Scikit-Learn kütüphanesi ile müşterilerine yeni müzikler önermektedir. Geçmişteki müzik dinlemeleri ve müzik türleri hakkındaki veriler kullanılarak dinleyicilere daha önce dinlemedikleri ve dinlemek isteyebilecekleri müzikler önerilir. Diğer bir örnek de not alma uygulaması olan Evernote uygulamasıdır. Evernote da Scikit-Learn kütüphanesini sıklıkla projelerinde kullanmaktadır.
Scikit-Learn Kütüphanesinin Yüklenmesi#
Scikit-Learn kütüphanesini bilgisayara yüklemek için aşağıdaki şekilde gösterilen komutların komut istemcisine veya Anaconda Prompt içerisine yazılması gereklidir. Ancak Anaconda yüklemesi gerçekleştirilince Scikit-Learn kütüphanesi de yüklü gelmektedir. O nedenle yeniden yüklenmesine gerek yoktur. Eğer farklı bir ortamda çalışılacaksa ortam içerisine Scikit-Learn kütüphanesinin eklenmesi için bu yöntem kullanılabilir.

Yükleme doğrulandıktan sonra Jupyter notebook içerisinde aşağıdaki kodlar yardımıyla Scikit-Learn kütüphanesi çağrılabilir.
import sklearn as sk
import numpy as np
import pandas as pd
sk.__version__
'0.24.2'
Kitapta kullanılan versiyon 0.24.1 versiyonudur. İlerleyen kısımlardaki bazı kodlar farklı versiyonlarda doğru çalışmayabilir.
Scikit-Learn Veri Setleri#
Veri madenciliği yöntemlerinin uygulanabilmesi için veri setlerine ihtiyaç vardır. Veri setleri kaynaklarından birisi de Scikit-Learn veri setleridir. Bu kaynağın içerisinde de bilinen ve sıklıkla kullanılan veri setleri yer almaktadır. Yani Scikit-Learn veri setleri genellikle çok ön işleme aşaması gerektirmeyen, analize hazır veri setleridir. Makine öğrenmesinde kullanılan veri setleri çoğunlukla 2 boyutludur yani tablo formatındadır. Tablodaki her satır bir veriyi temsil eder. Sütunlar ise özellikleri gösterir. Aşağıdaki görselde Boston veri seti için satırlar ve sütunlar gösterilmiştir.
Veri setleri Scikit-Learn kütüphanesi ile gelmektedir. Eğer kütüphane yüklemesi tamamlandıysa veri setleri de bilgisayara yüklenmiş olacaktır. Veri setleri bilgisayarda csv dosyaları şeklinde bulunabilir. Bu işlem için izlenmesi gereken yol “ANACONDA YÜKLEME KLASÖRÜ”\pkgs\scikit-learn-0.24.1-py37hf11a4ad_0\Lib\site-packages\sklearn\datasets\data”.
 Veri setlerine bilgisayardan ulaşma
Veri setlerine bilgisayardan ulaşma
Scikit-Learn veri setleri “toy” veri setleri olarak bilinir. Yani makine öğrenmesine yeni giriş yapacak kişiler için önerilen veri setlerinden bahsedilmektedir. Bu veri setleri hakkında kısaca bilgi verilmesi gerekirse;
Boston Ev Fiyatları (boston_house_prices.csv): Binanın yaşı, dairenin oda sayısı, binanın bulunduğu bölgedeki suç oranı gibi birtakım özelliklere bakılarak Boston eyaletindeki evlerin fiyatlarının bulunduğu veri setidir. Bu özellikler kullanılarak bir evin fiyatı tahmin edilmeye çalışılır.
Meme Kanseri (breast_cancer.csv): Bir tıp veri setidir.
Diyabet (diabetes_data.csv): Diyabet hastalığı veri setidir.
Zambak Çiçeği (iris.csv): Zambak çiçeğinin türlerinin olduğu veri setidir.
Şarap Verileri (wine_data.csv): Şarap verilerine ait veri setidir.
Bu veri setleri Jupyter notebooka çağrılırken sklearn.datasets içerisinden çağrılır. Aşağıdaki yöntem ile tüm veri setleri Jupyter notebook içerisine alınmış olunur.
from sklearn import datasets
boston = datasets.load_boston()
type(boston)
sklearn.utils.Bunch
Veri setlerinin kendilerine ait “load_VERİSETİ()” şeklinde bir yapısı mevcuttur. Dolayısıyla veri seti çağrılırken “load_boston()” ile çağrıldı. Aynı şekilde eğer meme kanseri veri seti çağrılmak istenseydi “load_breast_cancer()” fonksiyonu ile çağrılması gerekirdi.
breast_cancer = datasets.load_breast_cancer()
type(breast_cancer)
sklearn.utils.Bunch
# Bunch içerisinde hangi anahtarlar var?
print(boston.keys())
# Anahtarların veri yapıları neler?
type(boston.data),type(boston.target),type(boston.DESCR),type(boston.feature_names)
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
(numpy.ndarray, numpy.ndarray, str, numpy.ndarray)
Görüldüğü gibi veri setlerinin veri yapısı Bunch olarak gösterilmektedir. Bunch Python sözlüklerinin Scikit-Learn kütüphanesindeki karşılığı olarak görülebilir. Daha önce bahsedildiği gibi sözlük içerisinde anahtar:değer ilişkileri bulunmaktadır. Sözlük içerisindeki anahtar(keys) değerleri girilerek karşılığında gelecek değerler alınır. Bu sözlüğü parçalayarak veri setinin içeriğinden bahsedilmek gerekirse aşağıdaki kodlar kullanılabilir.
Boston veri seti için geçerli olan bu anahtarlar diğer veri setleri için de geçerlidir. Anahtarlar genellikle NumPy dizisi veri tipinde tutulmuştur. Anahtarlar hakkında kısaca bilgiler aşağıda verilmiştir.
data (boston.data): Bir NumPy dizisi şeklinde verilerin tutulduğu anahtardır. NumPy dizilerinde sunulan avantajlardan faydalanılarak incelenebilir.
target(boston.target): Hedef değişkeninin tutulduğu anahtardır. Yine NumPy dizisi şeklinde tutulur. Data ve target veri yapıları veri setini oluşturacak şekilde ayarlanmıştır. Aşağıdaki görselde Scikit-Learn kütüphanesinde geçtiği şekilde veri setlerinde kullanılan kavramlar tekrar gösterilmiştir.
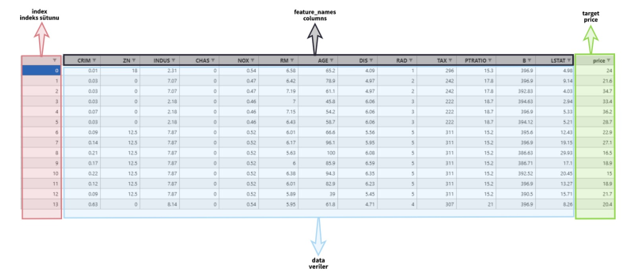
Scikit-Learn Veri Setlerinin Yapısı#
Boston veri setindeki veriler X değişkenine, hedef değişkeni de y değişkenine kaydedilebilir.
# X ve y değişkenleri
X = boston.data
y = boston.target
boston_features = pd.DataFrame(X, columns=boston.feature_names)
boston_features.head()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
dfy = pd.DataFrame(y,columns=['price'])
dfX = pd.DataFrame(X, columns=boston.feature_names)
df = dfX.join(dfy)
df.head()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
Veri Önişleme Aşaması#
Veri önişleme makine öğrenmesinde oldukça önemli bir aşamadır. Veri önişleme, veri setlerini temizleme, düzenleme ve hazırlama sürecidir. Bu süreç, verilerin doğru bir şekilde analiz edilebilmesi ve makine öğrenmesi modellerinin doğru sonuçlar vermesi için gereklidir.
Veri önişleme aşamaları şunları içerebilir:
Veri toplama: Makine öğrenmesi modeli oluşturmak için uygun verilerin toplanması gereklidir. Bu veriler, çeşitli kaynaklardan gelir ve genellikle büyük miktarda veri içerir.
Veri ön işleme: Verilerin temizlenmesi ve hazırlanması için birkaç adım gereklidir. Bu adımlar, verilerin düzenlenmesini, eksik verilerin giderilmesini ve verilerin normalleştirilmesini içerebilir. Ayrıca, verilerin özelliklerinin seçimi de bu adımda gerçekleştirilir.
Veri bölme: Veri setleri genellikle eğitim, test ve doğrulama setleri olarak bölünür. Eğitim seti, modelin eğitiminde kullanılır, test seti modelin doğruluğunu kontrol etmek için kullanılır ve doğrulama seti, modelin performansını izlemek için kullanılır.
Veri özellikleri seçimi: Veri setleri genellikle birçok özelliğe sahiptir. Bu özelliklerin sayısı, modelin karmaşıklığını artırabilir ve aynı zamanda modelin performansını düşürebilir. Bu nedenle, veri özellikleri seçimi yapılırken, gereksiz özelliklerin çıkarılması ve yalnızca önemli özelliklerin kullanılması gereklidir.
Veri normalleştirme: Veri setleri, farklı aralıklarda olabilen özellikler içerebilir. Bu nedenle, verilerin normalleştirilmesi gereklidir. Normalizasyon işlemi, verilerin ortalama değerinin sıfır ve standart sapmasının bir olduğu bir ölçekte yeniden ölçeklendirilmesini içerir.
Veri önişleme, makine öğrenmesinde oldukça önemlidir ve doğru bir şekilde yapılması, modelin doğruluğunu artırabilir.
Eğitim ve test setlerinin ayrılması#
Makine öğrenmesi modellerinin performansını ölçmek ve doğru sonuçlar elde etmek için, veriler eğitim seti ve test seti olarak ayrılmalıdır. Eğitim seti, modelin öğrenme sürecinde kullanılan veri kümesidir ve test seti, modelin doğruluğunu ölçmek için kullanılan veri kümesidir.
Eğitim seti, modelin öğrenmesinde kullanılan verilerdir. Model, bu verileri kullanarak özelliklerin arasındaki ilişkileri öğrenir ve sonunda bir tahmin yapmak için bu özellikleri kullanabilir. Eğitim setinin yeterince büyük ve temsil edici olması, modelin doğru bir şekilde öğrenmesi için önemlidir.
Test seti, modelin performansını ölçmek için kullanılan verilerdir. Model eğitildikten sonra, test setindeki verileri kullanarak tahminler yaparız ve gerçek sonuçlarla karşılaştırırız. Bu sayede modelin doğruluğunu ölçeriz ve gerektiğinde iyileştirmeler yaparız.
Veri kümesinin eğitim seti ve test seti olarak nasıl ayrılacağına karar vermek için farklı yöntemler kullanılabilir. En yaygın yöntem, verilerin belirli bir oranda rastgele bölünmesidir. Örneğin, verilerin %80’i eğitim seti olarak kullanılırken, %20’si test seti olarak kullanılabilir.
Eğitim ve test setleri ayrıldıktan sonra, eğitim seti üzerinde model eğitilir ve ardından test seti üzerinde doğrulama yapılır. Bu işlem, modelin gerçek dünya verilerinde nasıl performans gösterdiğini anlamak için önemlidir.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.20,
random_state=12345)
Bu kodlar, Scikit-learn kütüphanesinin model_selection modülünden train_test_split fonksiyonunu kullanarak, veri setini rastgele eğitim ve test alt kümelerine ayırmak için kullanılır.
X özellik matrisini, y hedef değişkenini ve test_size parametresi olarak verilen oranı kullanarak, veri setini eğitim ve test setleri olarak ayırır. random_state parametresi ise her seferinde aynı rastgele bölmenin oluşturulmasını sağlar.
Fonksiyon çağrısı sonucunda, X_train ve y_train eğitim setini, X_test ve y_test ise test setini temsil eder. Bu şekilde, veri seti iki ayrı alt kümeye ayrılarak, makine öğrenmesi modelinin eğitiminde kullanılan veri ile test edilmesi için kullanılan veri ayrılmış olur.
Eksik veriler#
df.isnull().sum()
CRIM 0
ZN 0
INDUS 0
CHAS 0
NOX 0
RM 0
AGE 0
DIS 0
RAD 0
TAX 0
PTRATIO 0
B 0
LSTAT 0
price 0
dtype: int64
# özet bilgileri sunalım.
df.describe()
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 | 506.000000 |
| mean | 3.613524 | 11.363636 | 11.136779 | 0.069170 | 0.554695 | 6.284634 | 68.574901 | 3.795043 | 9.549407 | 408.237154 | 18.455534 | 356.674032 | 12.653063 | 22.532806 |
| std | 8.601545 | 23.322453 | 6.860353 | 0.253994 | 0.115878 | 0.702617 | 28.148861 | 2.105710 | 8.707259 | 168.537116 | 2.164946 | 91.294864 | 7.141062 | 9.197104 |
| min | 0.006320 | 0.000000 | 0.460000 | 0.000000 | 0.385000 | 3.561000 | 2.900000 | 1.129600 | 1.000000 | 187.000000 | 12.600000 | 0.320000 | 1.730000 | 5.000000 |
| 25% | 0.082045 | 0.000000 | 5.190000 | 0.000000 | 0.449000 | 5.885500 | 45.025000 | 2.100175 | 4.000000 | 279.000000 | 17.400000 | 375.377500 | 6.950000 | 17.025000 |
| 50% | 0.256510 | 0.000000 | 9.690000 | 0.000000 | 0.538000 | 6.208500 | 77.500000 | 3.207450 | 5.000000 | 330.000000 | 19.050000 | 391.440000 | 11.360000 | 21.200000 |
| 75% | 3.677083 | 12.500000 | 18.100000 | 0.000000 | 0.624000 | 6.623500 | 94.075000 | 5.188425 | 24.000000 | 666.000000 | 20.200000 | 396.225000 | 16.955000 | 25.000000 |
| max | 88.976200 | 100.000000 | 27.740000 | 1.000000 | 0.871000 | 8.780000 | 100.000000 | 12.126500 | 24.000000 | 711.000000 | 22.000000 | 396.900000 | 37.970000 | 50.000000 |
Ölçeklendirme#
Makine öğrenmesi modellerinin performansı, verilerin ölçeği ile doğrudan ilişkilidir. Ölçeklendirme, verilerin farklı ölçeklerde veya aralıklarda olduğu durumlarda önemlidir. Örneğin, bir veri kümesinde bir özellik binlerce dolarlık aralıklarda iken, diğer bir özellik 0 ile 1 arasında bir aralığa sahip olabilir. Bu durumda, doğru sonuçlar almak için verilerin ölçeklendirilmesi gerekebilir.
Ölçeklendirme işlemi, verilerin belirli bir aralığa veya dağılıma getirilmesini içerir. Verileri ölçeklendirmek için yaygın olarak kullanılan iki yöntem vardır:
Normalizasyon: Verilerin belirli bir aralığa sığdırılması için kullanılır. Örneğin, verilerin 0 ile 1 arasında ölçeklendirilmesi için Min-Max normalizasyonu kullanılabilir.
Standartlaştırma: Verilerin bir standart dağılıma sahip olacak şekilde ölçeklendirilmesini sağlar. Bu, verilerin ortalama değerinden çıkarılması ve standart sapmaya bölünmesi ile yapılır.
MinMaxScaler ile Veri Ölçeklendirme#
fit(): ölçeklemede belirli bir verinin ortalamasını ve std sapmasını hesaplamak için kullanılır.transform(): fit() yöntemi ile hesaplanan ortalama ve std sapma kullanılarak ölçekleme gerçekleştirmek için kullanılır.The
fit_transform()hem fit hem de transform eder.
from sklearn.preprocessing import MinMaxScaler
mm_scaler = MinMaxScaler()
Ölçeklendirme, yalnızca eğitim kümesindeki verileri kullanarak, verileri eğitim ve test kümesi arasında böldükten sonra yapılmalıdır. Çünkü test seti görülmeyen yani yeni verileri göstermektedir. Eğitime test verilerinin katılmaması gerekir. Eğitimden önce ölçeklendirme yapmak bu nedenle doğru olmayacaktır.
X_train_scaled = mm_scaler.fit_transform(X_train)
print(mm_scaler.min_)
print(mm_scaler.scale_)
np.set_printoptions(precision=3, suppress=True)
print(X_train_scaled[:5])
[-7.10352762e-05 0.00000000e+00 -1.68621701e-02 0.00000000e+00
-7.92181070e-01 -6.82314620e-01 -2.98661174e-02 -1.02719857e-01
-4.34782609e-02 -3.56870229e-01 -1.34042553e+00 -6.38977636e-03
-4.77373068e-02]
[1.12397589e-02 1.00000000e-02 3.66568915e-02 1.00000000e+00
2.05761317e+00 1.91607588e-01 1.02986612e-02 9.09347180e-02
4.34782609e-02 1.90839695e-03 1.06382979e-01 2.53562554e-03
2.75938190e-02]
[[0.001 0. 0.236 0. 0.13 0.615 0. 0.418 0.087 0.088 0.564 0.971
0.086]
[0.001 0. 0.42 0. 0.387 0.654 0.907 0.094 0. 0.164 0.894 1.
0.108]
[0.006 0. 0.21 0. 0.245 0.464 0.671 0.231 0.304 0.229 0.511 0.953
0.274]
[0. 0.8 0.048 0. 0. 0.511 0.295 0.724 0. 0.103 0.596 0.86
0.309]
[0.001 0. 1. 0. 0.461 0.464 0.83 0.089 0.13 1. 0.798 1.
0.321]]
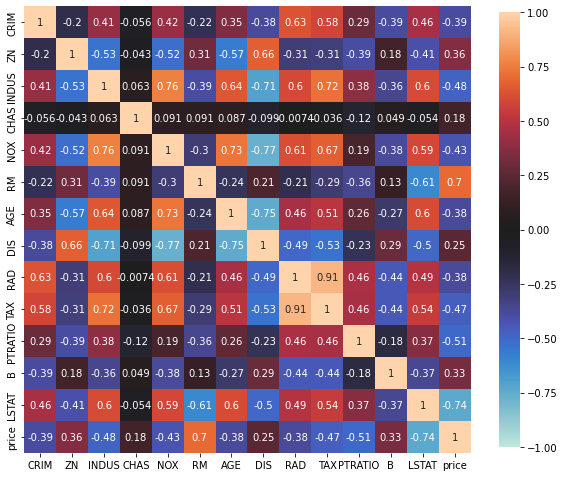
import seaborn as sns
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(10, 10))
sns.heatmap(df.corr(),center=0, vmin=-1, vmax=1, square=True, annot=True,cbar_kws={'shrink': 0.8})
<AxesSubplot:>
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null float64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null float64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 price 506 non-null float64
dtypes: float64(14)
memory usage: 55.5 KB
X.shape, y.shape # Orijinal veri seti
((506, 13), (506,))
X_train.shape, y_train.shape # eğitim veriseti
((404, 13), (404,))
X_test.shape, y_test.shape # test veri seti
((102, 13), (102,))
Doğrusal Regresyon#
Doğrusal regresyon, iki değişken arasındaki ilişkiyi anlamak için kullanılan bir istatistiksel modellemedir. Bu ilişki doğrusal olarak ifade edilir ve bir çıktı değişkeni (bağımlı değişken) ile bir veya daha fazla girdi değişkeni (bağımsız değişkenler) arasındaki ilişkiyi tanımlar. Doğrusal regresyon, özellikle sürekli sayısal verilerde, bir değişkenin diğer değişkenlerle olan ilişkisini anlamak ve tahminler yapmak için sıklıkla kullanılan bir yöntemdir. Doğrusal regresyon modelleri, verilerdeki değişkenliği açıklayan en az kareler yöntemi kullanılarak elde edilir.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
model = LinearRegression()
model.fit(X_train_scaled,y_train)
LinearRegression()
Bu kodlar, doğrusal regresyon modeli oluşturma ve eğitme işlemini gerçekleştirir. İlk olarak, sklearn.linear_model kütüphanesinden LinearRegression sınıfı çağrılır ve model adı verilen bir örnek oluşturulur. Daha sonra, fit() fonksiyonu kullanılarak oluşturulan model eğitilir. Bu işlem, X_train_scaled ve y_train veri setleri üzerinde gerçekleştirilir.
Ayrıca, doğrusal regresyon modelinin performansını değerlendirmek için sklearn.metrics kütüphanesinden r2_score, mean_absolute_error ve mean_squared_error fonksiyonları çağrılır. Bu fonksiyonlar, sırasıyla, R-kare skoru, ortalama mutlak hata ve ortalama karesel hata değerlerini hesaplar. Bu değerler, modelin doğruluğunu değerlendirmek için kullanılabilir.
Özetle, bu kodlar doğrusal regresyon modelini oluşturur, eğitir ve performansını değerlendirir.
print("katsayılar: ", model.coef_)
print("kesme terimi: ", model.intercept_)
print("katsayı sayısı: ", model.coef_.shape)
katsayılar: [ -9.421 4.949 0.774 2.974 -8.379 23.783 -0.556 -14.66 6.019
-5.746 -9.308 3.172 -16.17 ]
kesme terimi: 24.309530869937667
katsayı sayısı: (13,)
Burada:
model.coef_ ifadesi, öğrenilmiş regresyon modelinin her bir öznitelik için katsayılarını içeren bir NumPy dizisini döndürür.
model.intercept_ ifadesi, öğrenilmiş regresyon modelinin kesme terimini döndürür.
model.coef_.shape ifadesi, katsayı dizisinin şeklini gösterir, yani modelde kaç öznitelik olduğunu gösterir.
X_test_scaled = mm_scaler.transform(X_test)
mm_scaler.transform(X_test) kodu, önceden oluşturulan MinMaxScaler nesnesi olan mm_scaler’ı kullanarak test verilerinin ölçeklendirilmesini sağlar. X_test veri seti, önceden eğitilen ölçekleyici nesnesi mm_scaler ile ölçeklendirilir ve ölçeklendirilmiş test verileri X_test_scaled olarak kaydedilir. Bu, eğitim verileriyle aynı ölçeklendirme işleminin kullanıldığından emin olmak için önemlidir ve daha sonra test verileri üzerinde tahmin yapmak için kullanılacaktır.
y_predict = model.predict(X_test_scaled)
Modelin predict() metodu kullanılarak, önceden ölçeklendirilmiş test verileri olan X_test_scaled argümanı modelin tahmin etmesi için kullanılır ve sonuç y_predict değişkeninde saklanır. Bu sonuçlar daha sonra modelin performansını değerlendirmek için gerçek test hedefleri y_test ile karşılaştırılabilir.
y_predict
array([24.217, 31.641, 20.588, 22.856, 16.684, 14.317, 26.809, 25.617,
32.369, 16.666, 24.377, 16.778, 28.064, 16.162, 20.256, 20.495,
20.951, 33.067, 10.946, 17.373, 21.892, 19.969, 8.552, 25.359,
32.245, 30.801, 14.852, 27.706, 16.94 , 17.08 , 28.097, 19.534,
14.018, 10.163, 14.051, 25.358, 30.418, 19.687, 31.597, 21.768,
28.319, 14.314, 29.707, 17.699, 33.596, 28.267, 27.92 , 23.356,
17.563, 9.874, 20.834, 19.42 , 18.267, 19.79 , 33.428, 19.927,
19.93 , 36.306, 17.491, 37.359, 22.827, 19.233, 13.543, 17.412,
14.857, 34.159, 25.847, 36.226, 16.213, 34.577, 8.936, 27.602,
21.733, 29.249, 19.118, 32.53 , 31.958, 14.508, 27.029, 14.379,
20.339, 11.307, 25.34 , 24.702, 17.094, 17.761, 19.012, 21.203,
21.284, 19.444, 5.939, 28.83 , 20.001, 13.202, 21.267, 42.906,
20.044, 28.248, 24.296, 30.158, 16.669, 28.498])
y_test
array([21.7, 24.8, 20.6, 23. , 19.1, 15. , 22.6, 24.7, 27. , 20.8, 27.5,
19.1, 22. , 10.2, 18.3, 21.7, 21.2, 29. , 16.3, 19.9, 19.8, 15. ,
23.1, 26.5, 35.4, 31.5, 14.8, 24.8, 23.1, 13.4, 22.8, 18.4, 21.9,
17.8, 13.1, 24.2, 29.4, 19.5, 37. , 18.9, 24.5, 11.7, 22.5, 18.6,
28.5, 24.3, 25. , 22.4, 20.8, 14.4, 21.5, 22.2, 14.5, 17.7, 36.1,
19.3, 19.2, 38.7, 17.4, 33.3, 17. , 19.1, 13.1, 18.1, 9.6, 30.3,
19.4, 50. , 17.6, 34.9, 11.8, 26.6, 20.6, 30.1, 12.5, 33.2, 27.9,
7.5, 25.2, 19. , 21.8, 6.3, 23.3, 21.9, 14.9, 18.2, 20.6, 50. ,
21. , 18.9, 13.8, 28.6, 13.1, 15.6, 19.3, 50. , 21.8, 28.7, 25. ,
32.5, 17.3, 24.6])
Modelin Değerlendirilmesi#
Modelin değerlendirmesi, öncelikle belirlenen performans metrikleri kullanılarak yapılır. Bu metrikler, modelin ne kadar doğru sonuçlar verdiğini ölçer. Örneğin, sınıflandırma problemleri için doğruluk (accuracy), hassasiyet (precision), duyarlılık (recall) ve F1-score kullanılabilir. Regresyon problemleri için ise ortalama mutlak hata (mean absolute error), ortalama karesel hata (mean squared error) ve belki de belirlenen bir eşiğe göre doğruluğu ölçen bir metrik kullanılabilir.
Değerlendirme işlemi, eğitim verileri üzerinden eğitilen modelin test verileri üzerinde nasıl performans gösterdiğini ölçerek yapılır. Bunun için, öncelikle test verileri üzerinde modelin tahminleri hesaplanır ve gerçek sonuçlarla karşılaştırılır. Bu karşılaştırma sonucunda elde edilen performans metrikleri, modelin performansını değerlendirmeye yardımcı olur.
Ayrıca, bazı durumlarda çapraz doğrulama (cross-validation) gibi teknikler de kullanılabilir. Bu teknikler, farklı veri parçaları üzerinde modelin performansını değerlendirerek, sonuçların daha güvenilir olmasını sağlar. Bu örnekte R^2 kullanılacaktır. score() fonksiyonu determinasyon katsayısını verir.
model.score(X_train_scaled, y_train)
0.7586732434392979
# Determinasyon katsayısını verir.
model.score(X_train_scaled,y_train)
0.7586732434392979
r2_score(y_test,y_predict)
0.6160762605146681
# measure the performance of the model
mse = mean_squared_error(y_test, y_predict)
rmse = np.sqrt(mse)
print(rmse)
4.962046573144257
mse
24.621906194052666
Diğer metrikler için bu sayfadan daha fazla bilgi alınabilir.
Çapraz doğrulama#
Değerlendirme aşamasında bir diğer yaklaşım da çapraz doğrulamadır. Daha önce bahsedildiği gibi veri seti birden fazla eğitim ve test setine ayrılarak bir öğrenme gerçekleştirilir. Farklı sayıda gerçekleştirilen öğrenmelerin ortalaması alınarak daha geçerli sonuçlar üretilmiş olur. Çapraz doğrulama, veri kümesini eğitim ve test kümelerine ayırarak, modelin performansını ölçer ve aynı zamanda modelin genelleme yeteneğini de test eder. Scikit-learn kütüphanesi, çapraz doğrulama yöntemlerini kullanarak makine öğrenimi modellerinin doğruluğunu değerlendirmek için bir dizi araç sunar. Bu araçlar arasında K-Fold çapraz doğrulama, ShuffleSplit, StratifiedKFold ve GroupKFold yer alır.
K-Fold çapraz doğrulama, veri kümesini k eşit parçaya ayırarak çalışır ve her bir parçayı sırayla test kümesi olarak kullanır. Kalan k-1 parça ise eğitim kümesi olarak kullanılır. Bu işlem, k kez tekrarlanır ve sonuçlar ortalaması alınarak modelin performansı ölçülür. Bu yöntem, bir veri kümesinin tamamının kullanılmasını sağladığı için daha güvenilir sonuçlar verir.
ShuffleSplit yöntemi, veri kümesini belirli sayıda rastgele parçaya ayırır ve bu parçaların her birini test kümesi olarak kullanır. Bu yöntem, K-Fold yöntemine göre daha hızlıdır ve daha büyük veri kümeleri için daha uygun olabilir.
StratifiedKFold yöntemi, sınıflandırma problemleri için kullanılır ve her bir katmanda sınıfların oranlarını korumaya çalışır. Bu yöntem, özellikle dengesiz sınıf dağılımlarına sahip veri kümelerinde daha iyi sonuçlar verir.
GroupKFold yöntemi, veri kümesinde belirli gruplar veya kümeler varsa, bu grupları test ve eğitim kümeleri olarak korumaya çalışır. Örneğin, bir kullanıcının birden fazla örneği varsa, bu örnekler aynı test veya eğitim kümesinde yer almayacak şekilde ayarlanır.
Scikit-learn kütüphanesi, bu yöntemlerin yanı sıra başka çapraz doğrulama yöntemleri de sunar. Bu yöntemler, makine öğrenimi modellerinin performansını doğru bir şekilde değerlendirmek için önemli bir araçtır ve modelin genelleme yeteneğini test etmek için kullanılırlar.
Scikit-learn kütüphanesi kullanarak K-Fold çapraz doğrulama yöntemini uygulayabiliriz. Örneğin, boston veri kümesindeki çıktıları tahmin etmek için bir karar ağacı sınıflandırıcısı eğitmek istediğimizi varsayalım. Aşağıdaki kod örneği, bu işlemi gerçekleştirecektir:
from sklearn.model_selection import cross_val_score
# K-Fold çapraz doğrulama yöntemini kullanarak modelin doğruluğunu ölç
scores = cross_val_score(model, X, y, cv=5)
# Sonuçları yazdır
print("Doğruluk: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
Doğruluk: 0.35 (+/- 0.75)
Burada cross_val_score fonksiyonu, veri kümesini K-Fold çapraz doğrulama yöntemiyle bölerek modelin doğruluğunu ölçer. Fonksiyon, modelin her bir test seti için doğruluğunu hesaplar ve sonuçları bir dizi olarak döndürür. Daha sonra, bu sonuçların ortalama doğruluğunu ve standart sapmasını hesaplayarak, modelin performansının ne kadar tutarlı olduğunu ölçeriz.
Tahminlerin karşılaştırılması#
Makine öğrenmesinde model performansının değerlendirilmesi için farklı metrikler kullanılır. Bu metrikler, modelin tahminlerinin gerçek değerlerle ne kadar iyi eşleştiğini ve ne kadar doğru olduğunu ölçer.
Bir sınıflandırma modeli için kullanılan bazı performans metrikleri şunlardır:
Confusion Matrix (Karmaşıklık Matrisi): Modelin doğruluğunu değerlendirmek için gerçek ve tahmini sınıfları görsel olarak gösterir.
Accuracy (Doğruluk): Tahmin edilen sınıfların doğru sınıfların yüzdesi olarak hesaplanır.
Precision (Hassasiyet): Pozitif olarak tahmin edilen örneklerin gerçekten pozitif olanların yüzdesi olarak hesaplanır.
Recall (Duyarlılık): Gerçekten pozitif olan örneklerin, pozitif olarak tahmin edilenlerin yüzdesi olarak hesaplanır.
F1 Score: Precision ve recall metriklerinin harmonik ortalamasıdır. Bir modelin hem hassasiyet hem de duyarlılık açısından iyi performans göstermesi gerektiğinde kullanılır.
Regresyon modelleri için ise kullanılan bazı performans metrikleri şunlardır:
Mean Squared Error (MSE): Gerçek ve tahmin edilen değerler arasındaki farkların karelerinin ortalamasını hesaplar.
Root Mean Squared Error (RMSE): MSE’nin karekökünü alarak elde edilir. Gerçek ve tahmin edilen değerler arasındaki farkın ortalamasıdır.
R-Squared (R²): Tahmin edilen değerlerin gerçek değerlerin varyansını açıklama yüzdesini hesaplar. 1’e yakın bir R² değeri, modelin iyi bir uyum sağladığını gösterir.
Bu metrikler, modelin başarısını objektif bir şekilde değerlendirmemizi sağlar ve geliştirme sürecinde ne yapmamız gerektiği hakkında ipuçları sağlar. Diğer yöntemde ise görsel karşılaştırma, tahminlerin gerçek değerlerle karşılaştırılması için kullanılan bir yöntemdir. Bu yöntemde genellikle çizgi grafikleri veya dağılım grafikleri kullanılır.
plt.plot(y_test, label='gerçek değerler')
plt.plot(y_predict, label='tahmin değerleri');
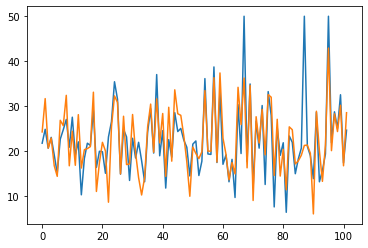
Bu kodlar matplotlib kütüphanesi ile birlikte kullanılarak gerçek ve tahmin edilen değerlerin görselleştirilmesini sağlar.
plt.plot(y_test, label='gerçek değerler') kodu gerçek değerlerin grafiğini çizerken plt.plot(y_predict, label='tahmin değerleri') kodu ise tahmin edilen değerlerin grafiğini çizer. Her iki grafiği karşılaştırmak için aynı grafik üzerinde çizilir ve her bir grafiğin etiketi belirtilir.
Bu şekilde, gerçek ve tahmin edilen değerlerin benzerlikleri veya farklılıkları hakkında görsel bir karşılaştırma yapılabilir.
Sonuç#
Bu bölümde, makine öğrenmesinde veri önişleme ve model değerlendirme konuları ele alınmıştır. Veri önişleme aşamaları, verilerin temizlenmesi, ölçeklendirilmesi, aykırı veri analizi, eğitim ve test setlerinin ayrılması ve daha fazlasını içerir. Model değerlendirme, model performansının değerlendirilmesi, tahminlerin gerçek değerlerle karşılaştırılması, görsel karşılaştırma gibi konuları kapsar. Bu bölümde kullanılan örneklerde, sklearn kütüphanesi kullanılarak veri önişleme işlemleri ve model değerlendirme teknikleri uygulanmıştır. Diğer makine öğrenmesi algoritmaları ile ilgili geliştirilecek uygulamalara ilerleyen bölümlerde yer verilecektir.
Kaynaklar#
Buitinck, L., Louppe, G., Blondel, M., et al. “API design for machine learning software: experiences from the scikit-learn project”, ECML PKDD Workshop: Languages for Data Mining and Machine Learning, pp. 108–122 (2013).