Pandas ile Veri Analizi ve İşleme#
Bu bölümde, temel pandas veri yapılarını oluşturmadan verileri pandas ile analiz etmeye kadar, pandas’ın veri işleme ve analizi alanındaki yeteneklerini uygulama örnekleri ve pratik egzersizlerle göstererek size yardımcı olacak bir kısa bir kurs olarak verilmiştir. Bu bölümün sonunda, veri okuma ve yazma, veri çerçeveleri birleştirme, veri ön işleme, veri görselleştirme vb. temel deneyimleri kazanmış olacaksınız. Daha sonraki bölümlerinde daha ayrıntılı bir şekilde ele alacağımız kütüphanenin çoğu temel özelliklerini bu bölümde belirteceğiz.
Python Pandas kütüphanesi, veri analizi ve işleme için kullanılan açık kaynaklı bir kütüphanedir. Bu kütüphane, veri manipülasyonu, filtreleme, görselleştirme ve veri analizi gibi birçok işlemi kolaylaştırır. Python programlama dilinde Pandas kütüphanesi kullanarak veri analizi yapmak oldukça kolaydır.
Bu yazıda, Python Pandas kütüphanesi hakkında genel bir bilgi edineceğiz ve kütüphane ile nasıl veri analizi yapabileceğimizi öğreneceğiz.
pandas Kütüphanesi#
Pandas, Python programlama dilinde veri analizi için kullanılan bir kütüphanedir. Veri manipülasyonu, veri filtreleme, veri birleştirme, veri işleme, veri analizi ve veri görselleştirme gibi birçok işlemi yapmamıza yardımcı olur. Pandas, verileri düzenlemek, analiz etmek ve modellemek için yaygın olarak kullanılan bir araçtır.
Pandas kütüphanesi, iki temel veri yapıları olan DataFrame ve Series sınıflarına dayanmaktadır. DataFrame, iki boyutlu bir veri yapısıdır ve sütunlar ve satırlar şeklinde organize edilir. Series, bir boyutlu bir veri yapısıdır ve sadece bir sütun içerir.
Nasıl yüklenir?#
Pandas kütüphanesi, Python programlama dilinin bir varsayılan kütüphanesi değildir ve sonradan yüklenmesi gerekmektedir. Pandas kütüphanesini yüklemek için aşağıdaki komutu kullanabilirsiniz:
pip install pandas
import pandas as pd
import numpy as np
pd.__version__ # pandas versiyonu: '1.3.4'
'1.3.4'
pandas kullanım alanları#
Pandas, Python programlama dilinde yüksek performanslı ve kullanımı kolay veri analizi ve manipülasyonu kütüphanesidir. Pandas, özellikle tablo benzeri yapıdaki veriler üzerinde çalışmak için tasarlanmıştır ve sütun ve satırların adlandırılmasına ve indekslenmesine izin verir. Pandas ayrıca, veri okuma ve yazma işlemleri için de birçok araç sağlar.
Pandas kütüphanesi ile yapılabilecek işlemler şu şekilde özetlenebilir:
Veri Okuma ve Yazma
Veri Seçme ve Sıralama
Veri Dönüştürme ve Temizleme
Veri Gruplama ve Birleştirm
Zaman Serisi Analizi
Veri Görselleştirme
Veri Modelleme ve Karşılaştırma
Veri Yapıları#
Pandas kütüphanesi, üç temel veri yapısı olan DataFrame, İndeks ve Series sınıflarına dayanmaktadır: Seriler (Series), Indeksler (Indexes) ve Veri Çerçeveleri (DataFrames).
Seriler (Series)#
Seriler, tek boyutlu bir veri yapısıdır ve birbirinden farklı veri tiplerini içerebilirler. Seriler, indeks ve değerlerden oluşur. Indeksler varsayılan olarak 0’dan başlayan tam sayılar olarak atanabilir veya belirtilen etiketleri kullanarak özelleştirilebilirler.
Seriler, bir boyutlu bir veri yapısıdır ve sadece bir sütun içerir. Seriler, bir liste, dizi veya sözlük gibi bir veri yapısından oluşturulabilir. Seriler aslında veri çerçevesinin sütununu temsil eder.
Aşağıdaki örnekte, bir Seriler nesnesi oluşturulup nesne üzerinde işlemler gösterilmiştir. Örnekler Jupyter Notebook üzerinde gerçekleştirilmiştir.
import pandas as pd
veriler = [1, 2, 5, 8]
seri_ornegi = pd.Series(veriler)
print(seri_ornegi)
0 1
1 2
2 5
3 8
dtype: int64
Aşağıdaki kod parçacıklarında Seriler hakkında çeşitli metotlara örnekler verilmiştir.
print(seri_ornegi.dtype) # int64
print(seri_ornegi.values) # [1 2 5 8]
print(seri_ornegi.name) # seri_ornegi
print(seri_ornegi.shape) # (4,)
seri_ornegi2 = pd.Series(
[2, 3, 4], index=['a', 'b', 'c'],
name='seri_ornegi') # indeks değerlerinin değiştirilmesi
print(seri_ornegi2.index) # Index(['a', 'b', 'c'], dtype='object')
print(seri_ornegi[seri_ornegi > 2]) # 2den büyük veriler
sayilar = np.linspace(0, 10, num=5)
print(sayilar) # [ 0. 2.5 5. 7.5 10. ]
x = pd.Series(sayilar) # indeksler [0, 1, 2, 3, 4]
y = pd.Series(sayilar, index=pd.Index([1, 2, 3, 4, 5]))
print(x + y) # indekslere göre toplama yapılır.
# numpy da iki diziyi toplayınca
print(np.array([1, 1, 1]) + np.array([-1, 0, 1]))
int64
[1 2 5 8]
None
(4,)
Index(['a', 'b', 'c'], dtype='object')
2 5
3 8
dtype: int64
[ 0. 2.5 5. 7.5 10. ]
0 NaN
1 2.5
2 7.5
3 12.5
4 17.5
5 NaN
dtype: float64
[0 1 2]
print(2 in seri_ornegi) # seri örneğinde 2 değeri var mı?
print(10 in seri_ornegi) # False
True
False
Görüldüğü gibi Seriler tek boyutlu veri yapılarını temsil etmektedir. İki veya daha fazla boyuttaki veri tipleri ile ilgili ise Veri Çerçeveleri kullanılmaktadır.
Veri Çerçeveleri (DataFrames)#
Veri Çerçeveleri, iki boyutlu bir veri yapısıdır ve birden çok Seriden oluşur. Veri Çerçeveleri, sütunlara ve satırlara göre indekslenir ve her sütun bir Seri nesnesi temsil eder. Her sütun farklı bir veri türüne sahip olabilir. Veri Çerçeveleri, birçok veri kaynağından okunabilir ve birçok farklı şekilde dönüştürülebilir.
DataFrame, iki boyutlu bir veri yapısıdır ve sütunlar ve satırlar şeklinde organize edilir. DataFrame, tablo benzeri bir yapıya sahiptir ve her sütun bir Series nesnesidir. DataFrame’in her bir satırı, bir gözlem veya bir veri noktasını temsil eder. DataFrame, verileri işlemek ve manipüle etmek için birçok yöntem sağlar.
Aşağıdaki örnekte, “isim”, “yas” ve “sehir” sütunları olan bir DataFrame nesnesi oluşturur.
# Veri çerçevesi yardımı
pd.DataFrame?
data = {'isim': ['Ahmet', 'Mehmet', 'Ali', 'Ayşe'],
'yas': [28, 22, 30, 25],
'sehir': ['İstanbul', 'Ankara', 'İzmir', 'Bursa']}
df = pd.DataFrame(data)
df
| isim | yas | sehir | |
|---|---|---|---|
| 0 | Ahmet | 28 | İstanbul |
| 1 | Mehmet | 22 | Ankara |
| 2 | Ali | 30 | İzmir |
| 3 | Ayşe | 25 | Bursa |
Veri çerçevesi oluşturma yöntemleri#
Veri Çerçevelerini oluşturmak için yukarıdaki örnekte olduğu gibi tüm veriler listeler içerisine yazılabilir. Bununla birlikte birkaç yöntemden daha bahsetmemiz gerekirse aşağıdaki yöntemleri söyleyebiliriz.
# Veri Çerçevesi oluşturma 1. yöntem
veri_cercevesi = pd.DataFrame(np.random.rand(3, 2),
columns=['Sütun 1', 'Sütun 2'],
index=['a', 'b', 'c'])
veri_cercevesi
| Sütun 1 | Sütun 2 | |
|---|---|---|
| a | 0.470738 | 0.198176 |
| b | 0.372200 | 0.376816 |
| c | 0.769168 | 0.094494 |
Veri çerçevesi oluşturmada 2. yöntem olarak Python veri tiplerinden sözlükler (dictionary) kullanılabilir. Sözlükler key:value tiplerinden oluşur.
plakalar = {'istanbul':'34','sakarya':'54','kmaraş':'46'}
nufus_sayilari = {'istanbul':20000000,'sakarya':1000000,'kmaraş':900000}
sehirler = pd.DataFrame({'plaka kodları':plakalar,'nufuslar':nufus_sayilari})
print(sehirler)
plaka kodları nufuslar
istanbul 34 20000000
sakarya 54 1000000
kmaraş 46 900000
Eğer index ve sütun değerleri eşleşirse toplama gerçekleşir. Bu durumda sehirler + sehirler komutu aşağıdaki çıktıyı verir.
sehirler + sehirler
| plaka kodları | nufuslar | |
|---|---|---|
| istanbul | 3434 | 40000000 |
| sakarya | 5454 | 2000000 |
| kmaraş | 4646 | 1800000 |
sehirler iki boyutlu bir veri yapısına sahiptir. Bu veri yapısı Numpy nesnesine dönüştürülebilir. Bunun için kullanılması gereken komut to_numpy komutudur.
print(sehirler.columns) # Index(['plaka kodları', 'nufuslar'], dtype='object')
print(sehirler.values)
print(sehirler.values)
sehirler_numpy = sehirler.to_numpy()
Index(['plaka kodları', 'nufuslar'], dtype='object')
[['34' 20000000]
['54' 1000000]
['46' 900000]]
[['34' 20000000]
['54' 1000000]
['46' 900000]]
Veri Çerçevesi oluşturmanın üçüncü yöntemi de liste fonksiyonları kullanmaktır. Bu duruma örnek aşağıdaki kod parçacıklarında verilmiştir.
veri_listesi = [(n, n**2, n**3) for n in range(5)] # list comprehensions
pd.DataFrame(veri_listesi, columns=['n', 'karesi', 'kubu'])
| n | karesi | kubu | |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 2 | 4 | 8 |
| 3 | 3 | 9 | 27 |
| 4 | 4 | 16 | 64 |
Son olarak Veri Çerçeveleri random modülü ile oluşturulabilir.
np.random.seed(12345)
pd.Series(np.random.rand(5), name='rassal')
0 0.929616
1 0.316376
2 0.183919
3 0.204560
4 0.567725
Name: rassal, dtype: float64
np.random.seed(12345)
disari_cikma = pd.DataFrame(
{
'rassal': np.random.rand(5),
'hava durumu': ['sicak', 'ilik', 'soguk', 'yagmurlu', 'karli'],
'karar': [np.random.choice(['Dışarı Çık', 'Dışarı Çıkma']) for _ in range(5)]
},
index=pd.date_range(start='1/1/2018',
freq='1D',
periods=5,
name='tarih'))
disari_cikma
| rassal | hava durumu | karar | |
|---|---|---|---|
| tarih | |||
| 2018-01-01 | 0.929616 | sicak | Dışarı Çıkma |
| 2018-01-02 | 0.316376 | ilik | Dışarı Çıkma |
| 2018-01-03 | 0.183919 | soguk | Dışarı Çık |
| 2018-01-04 | 0.204560 | yagmurlu | Dışarı Çıkma |
| 2018-01-05 | 0.567725 | karli | Dışarı Çıkma |
Veri Çerçevesindeki herhangi bir sütuna ulaşmak için iki yöntem kullanılabilir. Birincisinde köşeli parantez içerisinde sütun ismi verilir. Bu durumda sütun isminde boşluk gibi durumların olması çağırmayı etkilemez. İkinci yöntem olan nokta kullanımında ise boşluk gibi özel karakterlerin kullanılması mümkün değildir. Bu kullanımlara örnekler aşağıda verilmiştir.
print(disari_cikma["karar"]) # dışarı çıkma kararı series oldu
print(disari_cikma.karar)# yukarıdaki ile aynı kullanıma sahiptir.
tarih
2018-01-01 Dışarı Çıkma
2018-01-02 Dışarı Çıkma
2018-01-03 Dışarı Çık
2018-01-04 Dışarı Çıkma
2018-01-05 Dışarı Çıkma
Freq: D, Name: karar, dtype: object
tarih
2018-01-01 Dışarı Çıkma
2018-01-02 Dışarı Çıkma
2018-01-03 Dışarı Çık
2018-01-04 Dışarı Çıkma
2018-01-05 Dışarı Çıkma
Freq: D, Name: karar, dtype: object
Indeksler (Index)#
Pandas Serilerini numpy tek boyutlu dizilerden ayıran nokta indeks değerleridir. Indeks veri tipi sayesinde satır kayıtlarına etiketler ile ulaşılabilir.
indexler = seri_ornegi.index
print(indexler) # Index(['a', 'b', 'c'], dtype='object')
print(type(indexler)) # <class 'pandas.core.indexes.base.Index'>
print(indexler.is_unique) # indeksler tekil verilerden mi oluşuyor mu? True
# indeksler: Değiştirilemez listelerdir.
indeks_1 = pd.Index([1,2,3,4])
indeks_2 = pd.Index([3,4,5])
print(indeks_1.intersection(indeks_2)) # Kesişim: Int64Index([3, 4], dtype='int64')
print(indeks_1.union(indeks_2)) # Birleşim Int64Index([1, 2, 3, 4, 5], dtype='int64')
print(indeks_2.difference(indeks_1)) # Fark Int64Index([5], dtype='int64')
RangeIndex(start=0, stop=4, step=1)
<class 'pandas.core.indexes.range.RangeIndex'>
True
Int64Index([3, 4], dtype='int64')
Int64Index([1, 2, 3, 4, 5], dtype='int64')
Int64Index([5], dtype='int64')
Veri Giriş / Çıkış İşlemleri#
Pandas ile işlem yaparken çoğu kez farklı kaynak dosyalarından veri alma ve çıktıları farklı formatlarda yazmak gerekecektir. Bu işlemler, veri ile çalışırken vazgeçilmez işlemlerdir. Aşağıdaki komutlar ile, farklı dosya tipleri ile işlemler gerçekleştirilebilir.
text dosyası
genfromtxtcsv dosyası
read_csvExcel dosyası
read_exceljson dosyası
read_json()Veritabanından
read_sql()
Verilerin Okunması#
Burada bir uygulama üzerinde veri giriş çıkış ve kayıt işlemleri gerçekleştirilecektir. Uygulama için bu adreste yer alan veri seti kullanılacaktır.
# CSV dosyasının okunması
calisan_verileri = pd.read_csv("https://figshare.com/ndownloader/files/40286887",
skiprows=0,
sep=',',
header=0,
index_col=0)
calisan_verileri
| Start Date | Last Login Time | Salary | Bonus % | Senior Management | Team | |
|---|---|---|---|---|---|---|
| Gender | ||||||
| Male | 8/6/1993 | 12:42 PM | 97308 | 6.945 | True | Marketing |
| Male | 3/31/1996 | 6:53 AM | 61933 | 4.170 | True | NaN |
| Female | 4/23/1993 | 11:17 AM | 130590 | 11.858 | False | Finance |
| Male | 3/4/2005 | 1:00 PM | 138705 | 9.340 | True | Finance |
| Male | 1/24/1998 | 4:47 PM | 101004 | 1.389 | True | Client Services |
| ... | ... | ... | ... | ... | ... | ... |
| NaN | 11/23/2014 | 6:09 AM | 132483 | 16.655 | False | Distribution |
| Male | 1/31/1984 | 6:30 AM | 42392 | 19.675 | False | Finance |
| Male | 5/20/2013 | 12:39 PM | 96914 | 1.421 | False | Product |
| Male | 4/20/2013 | 4:45 PM | 60500 | 11.985 | False | Business Development |
| Male | 5/15/2012 | 6:24 PM | 129949 | 10.169 | True | Sales |
1000 rows × 6 columns
Pandas içerisindeki önemli fonksiyonlardan birisi read_csvfonksiyonudur. Bu fonksiyon CSV dosyalarını pandas DataFrame veri yapısına dönüştürmek için kullanılır. Bu yöntem aşağıdaki parametrelerle çağrılabilir:
filepath_or_buffer: Okunacak CSV dosyasının yolu ya da URL’si.sep: Dosya içerisindeki sütunları ayırmak için kullanılacak ayırıcı karakteri belirtir. Varsayılan ayırıcı virgüldür.delimiter: Dosya içerisindeki sütunları ayırmak için kullanılacak ayırıcı karakteri belirtir. sep parametresiyle aynı işlevi görür.header: Başlık satırının (sütun adları) var olup olmadığını belirtir. Varsayılan değer infer ile, ilk satırdaki değerlere göre otomatik olarak belirlenir.index_col: Veri setinde hangi sütunun index olarak kullanılacağını belirtir.usecols: Hangi sütunların alınacağını belirtir. Varsayılan olarak tüm sütunlar alınır.dtype: Sütunların veri tiplerini belirtir.skiprows: Dosyadaki belirtilen satır sayısı kadar okunmadan atlanır.skipfooter: Dosyanın sonundan belirtilen satır sayısı kadar okunmadan atlanır.nrows: Okunacak maksimum satır sayısını belirtir.na_values: Boş veya eksik verilerin nasıl işleneceğini belirtir. Varsayılan olarak, herhangi bir boş veya eksik veri NAN olarak belirlenir.encoding: Dosyanın karakter kodlamasını belirtir.
Online kaynaktan veri okunması#
Pandas, web sayfalarından veya online kaynaklardan veri okumak için birkaç farklı yöntem sunar. Bunlar arasında read_html(), read_json(), read_csv() ve read_excel() gibi popüler yöntemler yer alır. Bu yöntemler, farklı dosya türlerini veya veri kaynaklarını okumak için kullanılabilirler.
Aşağıdaki örnekte, bir web sayfasından veri okunur ve DataFrame nesnesi olarak döndürülür:
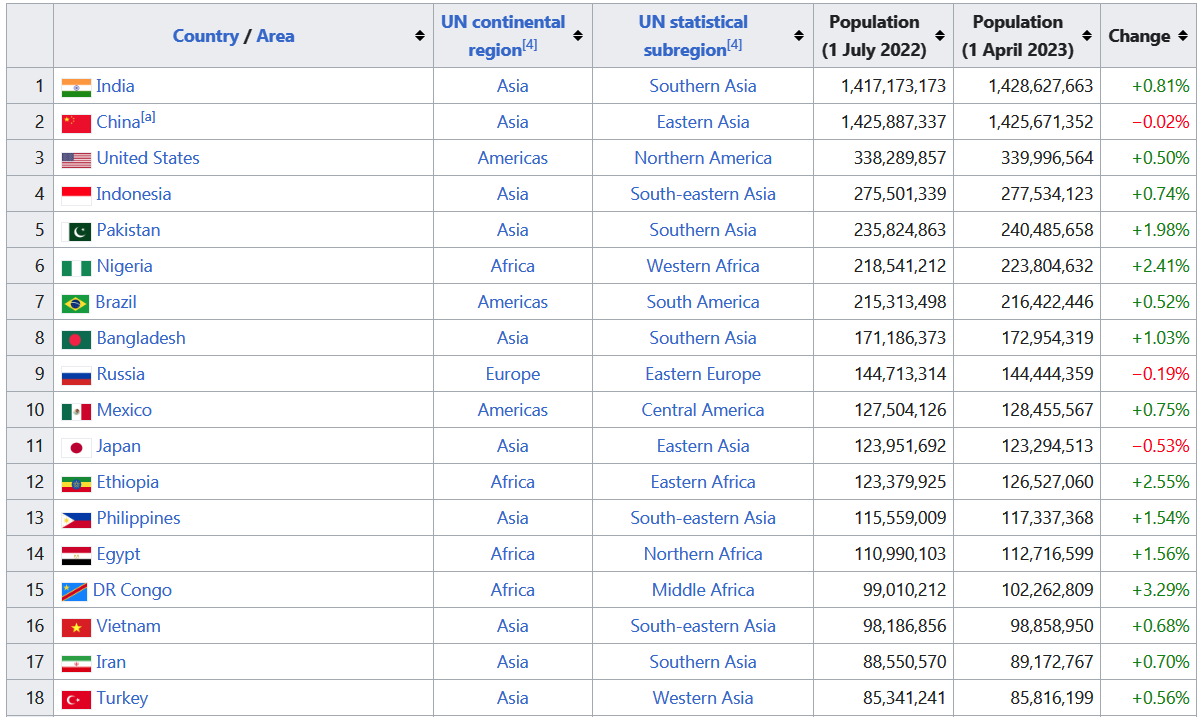
# Web sayfasındaki tablo verisini okuma
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
data = pd.read_html(url)
# İlk tabloyu alalım
df = data[0]
# DataFrame'i göster
df.head()
| Country / Area | UN continentalregion[4] | UN statisticalsubregion[4] | Population(1 July 2022) | Population(1 April 2023) | Change | |
|---|---|---|---|---|---|---|
| 0 | India | Asia | Southern Asia | 1417173173 | 1428627663 | +0.81% |
| 1 | China[a] | Asia | Eastern Asia | 1425887337 | 1425671352 | −0.02% |
| 2 | United States | Americas | Northern America | 338289857 | 339996564 | +0.50% |
| 3 | Indonesia | Asia | South-eastern Asia | 275501339 | 277534123 | +0.74% |
| 4 | Pakistan | Asia | Southern Asia | 235824863 | 240485658 | +1.98% |
Bu örnekte, pd.read_html() yöntemi, bir URL’yi parametre olarak alır ve bu URL’deki sayfada yer alan tüm tabloları içeren bir liste döndürür. Bizim örneğimizde, birinci tabloyu seçtik ve bir DataFrame nesnesi olarak döndürdük. Sonuç olarak, df değişkeni, web sayfasındaki ilk tabloyu içeren bir DataFrame nesnesi olarak oluşturuldu.
Ayrıca, pd.read_json() gibi diğer yöntemler de benzer şekilde kullanılabilir. Bu yöntemler, farklı veri türleri için özelleştirilmiş seçenekler ve parametreler sunarlar.
Verilerin Kaydedilmesi#
pandas kütüphanesi, farklı dosya biçimleri için çeşitli yazdırma metotları sunar. Bazı örnekler aşağıdaki gibidir:
to_csv: Bu metot, verileri bir CSV dosyasına yazdırmak için kullanılır.
# DataFrame'i bir CSV dosyasına yazdır
calisan_verileri.to_csv('calisan_verileri.csv', index=False)
Bu örnekte, to_csv() metodu kullanılarak bu veriler calisan_verileri.csv dosyasına yazdırılır. index=False parametresi, verilerin index sütununu dahil etmemeyi sağlar.
to_csv() yöntemi, verileri CSV dosyasına yazarken belirli bir klasöre kaydetmek için path_or_buf parametresini kullanır. Bu parametreye tam bir dosya yolu veya dosya adı verilebilir. Ayrıca, alt dizinleri de dahil ederek farklı klasörlere kaydetmek için dosya yolu belirtirken dizin adı da kullanılabilir.
normal şekilde kayıt
calisan_verileri.to_csv('./data/calisan_verileri.csv', index=False)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_4196/25051184.py in <module>
----> 1 calisan_verileri.to_csv('./data/calisan_verileri.csv', index=False)
D:\Anaconda3\lib\site-packages\pandas\core\generic.py in to_csv(self, path_or_buf, sep, na_rep, float_format, columns, header, index, index_label, mode, encoding, compression, quoting, quotechar, line_terminator, chunksize, date_format, doublequote, escapechar, decimal, errors, storage_options)
3464 )
3465
-> 3466 return DataFrameRenderer(formatter).to_csv(
3467 path_or_buf,
3468 line_terminator=line_terminator,
D:\Anaconda3\lib\site-packages\pandas\io\formats\format.py in to_csv(self, path_or_buf, encoding, sep, columns, index_label, mode, compression, quoting, quotechar, line_terminator, chunksize, date_format, doublequote, escapechar, errors, storage_options)
1103 formatter=self.fmt,
1104 )
-> 1105 csv_formatter.save()
1106
1107 if created_buffer:
D:\Anaconda3\lib\site-packages\pandas\io\formats\csvs.py in save(self)
235 """
236 # apply compression and byte/text conversion
--> 237 with get_handle(
238 self.filepath_or_buffer,
239 self.mode,
D:\Anaconda3\lib\site-packages\pandas\io\common.py in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
700 if ioargs.encoding and "b" not in ioargs.mode:
701 # Encoding
--> 702 handle = open(
703 handle,
704 ioargs.mode,
FileNotFoundError: [Errno 2] No such file or directory: './data/calisan_verileri.csv'
Bu örnekte, ./data yolunu kullanarak calisan_verileri.csv dosyasını data klasörü altında oluşturduk. Bu örneğin çalışabilmesi için çalışma klasörününün içerisine data adında bir klasör oluşturmak gerekmektedir. index=False parametresi, DataFrame’in satır dizinlerinin CSV dosyasına yazılmamasını sağlar. Eğer index=True olarak ayarlanırsa, satır dizinleri CSV dosyasına yazdırılacaktır.
Klasörlerin konumları ile ilgili şunları bilmek gereklidir.
‘./’ dizini, bulunduğumuz çalışma dizinini temsil eder. Bu nedenle, ‘./data’ ifadesi, bulunduğunuz dizin içindeki ‘data’ adlı bir alt dizine işaret eder. ‘.’ karakteri, mevcut dizini ifade etmek için kullanılır.
‘..’ ise bir üst dizini ifade eder. Örneğin, ‘../data’ ifadesi, mevcut dizinin bir üstündeki dizindeki ‘data’ adlı bir alt dizine işaret eder.
‘’ karakteri, Windows işletim sistemlerinde dosya yollarında kullanılan bir kaçış karakteridir. Bu karakter, dosya yolu bölümlerini ayırmak için kullanılır. Örneğin, “C:\Users\kullanici_adi\Desktop” ifadesinde, ‘’ karakterleri “C:”, “Users”, “kullanici_adi” ve “Desktop” gibi dosya yolu bölümlerini ayırmak için kullanılır. Unix tabanlı işletim sistemlerinde ise ‘/’ karakteri kullanılır.
Python’da da ‘’ karakteri kaçış karakteri olarak kullanılır. Ancak, Windows işletim sistemlerinde olduğu gibi dosya yollarında kullanılan ‘’ karakterleri yerine, Python’da Unix tabanlı işletim sistemlerinde olduğu gibi ‘/’ karakterleri kullanılır. Bunun nedeni, Windows işletim sisteminde ‘’ karakterinin kaçış karakteri olarak kullanılmasıdır ve dosya yollarında kullanılan ‘’ karakteri tek başına bir kaçış karakteri olarak algılandığından, dosya yolu yazımında hatalara yol açabilmektedir.
Bununla birlikte Python’da iki tane arka arkaya ‘’ karakteri, bir tanesi normal bir karakter olarak kabul edilip diğerinin kaçış karakteri olarak kabul edilmesini sağlamak için kullanılır. Örneğin, “\server\path\filename” ifadesinde, iki tane ‘’ karakteri, dosya yolunda kullanılan normal ‘’ karakterleri ve kaçış karakterleri arasında bir ayırıcı olarak işlev görür. Bu ifadede, ilk iki ‘’ karakteri, ‘\server’ dizini için normal ‘’ karakterleridir. Sonraki iki ‘’ karakteri, ‘\path’ dizini için normal ‘’ karakterleridir. Ve son olarak, son ‘’ karakteri, dosya adı olan ‘filename’ için normal ‘’ karakteridir.
osmodülü kullanarak kayıt
os modülü kullanarak da dosyaları farklı klasörlere kaydedebilirsiniz. Eğer data klasörü yoksa oluştur komutunu da burada verebilirsiniz. Örneğin:
import os
folder_path = './data'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
file_path = os.path.join(folder_path, 'calisan_verileri.csv')
calisan_verileri.to_csv(file_path, index=False)
Bu örnekte, os modülü kullanılarak öncelikle ./data klasörü oluşturulur. Daha sonra, os.path.join() yöntemi kullanarak calisan_verileri.csv dosyasının tam yolu oluşturulur ve DataFrame to_csv() yöntemi kullanılarak bu dosyaya yazdırılır.
to_excel: Bu metot, verileri bir Excel dosyasına yazdırmak için kullanılır. Örnek kullanımı:
# DataFrame'i bir Excel dosyasına yazdır
calisan_verileri.to_excel('calisan_verileri.xlsx', index=False)
Elde edilen Excel dosyası açıldığında aşağıdaki gibi düzgün bir çıktı alınacaktır.
Şekil 6 - Excel Ekran Görüntüsü |
to_sql: Bu metot, verileri bir SQL veritabanına yazdırmak için kullanılır.
pandas Veri Tipleri#
Pandas veri yapıları, aşağıdaki veri tiplerini içerebilir:
float: Ondalık sayıları temsil eder. Örneğin, 3.14 gibi.
int: Tam sayıları temsil eder. Örneğin, 42 gibi.
bool: True ve False mantıksal değerlerini temsil eder.
datetime: Tarih ve zaman değerlerini temsil eder. Örneğin, “2022-01-01 12:00:00” gibi.
timedelta: İki tarih veya zaman arasındaki farkı temsil eder.
object: Stringler, listeler, sözlükler, vb. nesneleri temsil eder.
Pandas, bu temel veri yapılarına ek olarak, Categorical ve Sparse veri yapıları da sunar. Categorical veri yapısı, kategorik verileri temsil etmek için kullanılır ve Sparse veri yapısı, verilerin seyrek veya büyük olduğu durumlarda bellek kullanımını optimize etmek için kullanılır.
dtypes, bir veri çerçevesinin tüm sütunlarının veri tiplerini gösteren bir özelliktir. Pandas DataFrame’i, farklı veri tiplerini (int, float, bool, string, datetime vb.) içeren sütunlardan oluşabilir. Her bir sütunun veri tipi, o sütundaki verilerin nasıl işleneceğini belirler.
dtypes, DataFrame’deki sütunların veri tiplerini gösteren bir Seri nesnesi döndürür. Bu özellik, DataFrame’deki her sütunun veri tipini belirlemek ve herhangi bir sütunun veri tipini değiştirmek gibi işlemler yapmak için kullanılabilir. Ayrıca, farklı veri tiplerine sahip sütunların DataFrame’deki verileri nasıl işlediğini anlamak için de kullanılabilir. Örneğin, bir sütunun tamsayı değerleri taşıması ve daha sonra ondalık sayılara dönüştürülmesi isteniyorsa, bu özellik, ilgili sütunun veri tipini değiştirmek için kullanılabilir.
calisan_verileri.dtypes
info() metodu ise, DataFrame’in bellekteki boyutunu, sütunların isimlerini, dolu hücrelerin sayısını ve her sütundaki veri tiplerinin sayısını görüntüler. Bu metot ayrıca bellekteki DataFrame’in bellek kullanımı ve veri tipleri hakkında da bilgi sağlar.
Ayrıca, her bir sütundaki eksik değerlerin sayısını ve veri tiplerinin bellek boyutunu da verir. Bu bilgi, veri seti üzerinde eksik değerlerin olduğu veya yanlış veri tipleri kullanıldığı durumlarda hataların nedenini anlamak için kullanılabilir.
calisan_verileri.info() # non-null sayılarını görmek için
Bununla birlikte bazı durumlarda veri tipleri arasında değişiklik yapılmak istenebilir. Bunun için astype() metodu kullanılabilir. Bu metot, Pandas DataFrame sütunlarının veri tiplerini değiştirmek için kullanılır. Bu yöntem, mevcut bir DataFrame’deki bir veya daha fazla sütunun veri tipini değiştirerek, veri analizi veya veri manipülasyonu için daha uygun bir formata dönüştürmeye olanak tanır.
Örneğin, bir sütunun veri tipini sayısal bir formattan tarih veya saat formatına dönüştürmek isteyebilirsiniz. Bu durumda, astype() yöntemini kullanarak sütunun veri tipini değiştirebilirsiniz.
Ayrıca, astype(), sayısal sütunları float veya integer veri tiplerine dönüştürerek hesaplama işlemlerinin hızını arttırmaya da yardımcı olabilir.
calisan_verileri['Salary'] = calisan_verileri['Salary'].astype(float)
Yukarıdaki örnekte, astype() yöntemi kullanılarak ‘Salary’ sütununun veri tipi integer’dan float’a değiştirildi.
calisan_verileri.dtypes
Veriler arasındaki dönüşümler#
Pandas, bir veri tipinden diğerine dönüştürmek için birkaç farklı seçenek sunar. Bazı yaygın dönüşüm işlemleri şunları içerir:
astype(): Bu yöntem, bir DataFrame sütununu veya Serisi’ni başka bir veri tipine dönüştürmek için kullanılır. Örneğin, bir sayısal sütunu metinsel bir sütuna dönüştürebilirsiniz. Bu yöntem, belirli bir veri tipi için bir seçenek belirleyebilir veya geniş bir yelpaze sunancategory,datetime64,timedeltavb. gibi özel veri tipleri için kullanılabilir.
to_numeric(): Bu yöntem, bir seriyi sayısal veri tipine dönüştürmek için kullanılır. Örneğin, bir serinin object veri tipinden float veya int veri tipine dönüştürebilirsiniz.
to_datetime(): Bu yöntem, bir Serisi’ni tarih / saat veri tipine dönüştürmek için kullanılır. Örneğin, bir seriyi object veya string veri tipinden datetime64 veri tipine dönüştürebilirsiniz.
to_timedelta(): Bu yöntem, bir seriyi zaman aralığı (timedelta) veri tipine dönüştürmek için kullanılır. Örneğin, bir seriyi “object” veya “string” veri tipinden “timedelta” veri tipine dönüştürebilirsiniz.
Aşağıdaki örnekler, bir veri tipinin diğerine nasıl dönüştürüleceğini gösterir:
# astype() yöntemi
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['x', 'y', 'z']})
df['A'] = df['A'].astype(str) # 'A' sütununu str veri tipine dönüştürür
df['B'] = df['B'].astype('category') # 'B' sütununu category veri tipine dönüştürür
# to_numeric() yöntemi
s = pd.Series(['1', '2', '3'])
s = pd.to_numeric(s) # Serisi'ni sayısal veri tipine dönüştürür
# to_datetime() yöntemi
s = pd.Series(['2021-01-01', '2021-02-01', '2021-03-01'])
s = pd.to_datetime(s) # Serisi'ni datetime64 veri tipine dönüştürür
# to_timedelta() yöntemi
s = pd.Series(['1 days', '2 days', '3 days'])
s = pd.to_timedelta(s) # Serisi'ni timedelta veri tipine dönüştürür
Bu örneklerde, astype(), to_numeric(), to_datetime() ve to_timedelta() yöntemleri kullanılarak farklı veri tiplerinin dönüşümü, verilerin analizi sırasında sık sık gereklidir. Pandas, çeşitli veri tipleri arasında dönüşüm yapabilen esnek bir kütüphanedir.
Bununla birlikte, dönüştürme işlemlerinin her zaman otomatik olarak başarılı olması garanti edilemez. Verilerin doğru şekilde dönüştürülüp dönüştürülmediğini kontrol etmek için, dönüştürme işlemi sonrası verilerin tekrar kontrol edilmesi önemlidir. Ayrıca, verileri dönüştürmek, verilerin boyutlarını da değiştirebilir. Bu nedenle, dönüştürme işlemi sırasında oluşabilecek olası veri kaybı veya hataların farkında olmak da önemlidir.
Veri Seti Üzerinde İşlemler#
Veri seti çok sayıda veriden oluşmaktadır. Bu nedenle veri setinin doğru şekilde alındığını göstermek açısından ilk satırlarının yazdırılması faydalı olacaktır. Bunun için head() metodu kullanılabilir.
calisan_verileri.head()
calisan_verileri.head(2) # ilk 2 veri
print(calisan_verileri.empty) # False
print(calisan_verileri.shape) # (1000, 7),
print(type(calisan_verileri)) # <class 'pandas.core.frame.DataFrame'>
print(calisan_verileri.columns)
print(
"bu veri setinde {} adet veri vardır. Ayrıca özellik sayısı {}'dir.".
format(calisan_verileri.shape[0], calisan_verileri.shape[1]))
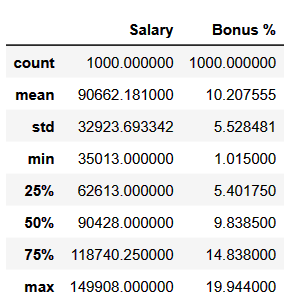
Pandas kütüphanesi DataFrame ve Series veri tiplerinde kullanılan describe() fonksiyonu, temel istatistiksel bilgileri özetleyen bir tablo oluşturur. Bu istatistiksel bilgiler arasında ortalama, standart sapma, minimum değer, maksimum değer, medyan, çeyreklikler ve veri sayısı yer alır.
describe() fonksiyonu, özellikle veri setinin özetini hızlı bir şekilde elde etmek istediğinizde kullanışlıdır. Fonksiyon, sayısal verilerin yanı sıra kategorik veriler hakkında da bazı temel istatistiksel bilgiler sağlar.
calisan_verileri.describe() # veri özetleme
Bu örnekte, describe() fonksiyonu calisan_verileri DataFrame’ine uygulanmış ve istatistiksel bilgileri özetleyen bir tablo oluşturulmuştur.
Bu tablo, maaş ve Bonus sütunları için temel istatistiksel bilgileri özetlemektedir. Çıktı aşağıdaki gibi görünecektir:
describe() fonksiyonu, varsayılan olarak sadece sayısal sütunlar için çalışır. Bununla birlikte, include parametresi kullanılarak belirli sütun türleri de tanımlanabilir. Örneğin, tüm sütunlar için istatistiksel özet bilgileri almak için include='all' parametresi kullanılabilir.
describe() fonksiyonunun ayrıca percentiles parametresi de vardır. Bu parametre, özet istatistiklerindeki çeyreklikleri belirlemek için kullanılan yüzde değerleri tanımlamak için kullanılabilir. Varsayılan olarak, percentiles parametresi [0.05, 0.95] olarak ayarlanmıştır.
Ayrıca, bu fonksiyonu varsayılan olarak tüm sütunlardaki eksik değerleri atlar. Bu davranış, include='all' parametresiyle aşılabileceği gibi, ayrıca dropna=False parametresi kullanılarak da değiştirilebilir. Bu, eksik değerlerin de dahil edilmesini sağlar ve eksik değerlerin sayısını özet istatistiklerinde gösterir.
calisan_verileri.describe(percentiles=[0.05, 0.95]) # diğer dilimleri de görüntülemek için
Veri çerçevesinde veri manipülasyonu, analizi ve temizliği için kullanılan pandas kütüphanesi, veri çerçevesi objeleriyle ilgili birçok metot içermektedir. Bu metotlar, veri işleme sürecinde oldukça yararlıdır. Aşağıda, bazı önemli veri çerçevesi metotları ve kısa açıklamaları yer almaktadır:
head(): Veri çerçevesinin ilk birkaç satırını görüntüler.tail(): Veri çerçevesinin son birkaç satırını görüntüler.drop(): Veri çerçevesinden belirtilen sütun veya satırları çıkarır.groupby(): Belirli bir sütuna göre verileri gruplar.merge(): İki veya daha fazla veri çerçevesini belirtilen sütuna göre birleştirir.sort_values(): Belirli bir sütuna göre verileri sıralar.pivot_table(): Veri çerçevesindeki verileri bir tablo halinde yeniden düzenler.isna() / isnull(): Veri çerçevesindeki boş değerleri (NaN) tespit eder.fillna(): Veri çerçevesindeki boş değerleri belirli bir değerle doldurur.drop_duplicates(): Veri çerçevesindeki tekrarlayan satırları çıkarır.apply(): Veri çerçevesinde belirtilen işlevi sütunlar veya satırlar üzerinde uygular.map(): Belirtilen bir işlevi veri çerçevesinin belirli bir sütununa veya serisine uygular.replace(): Belirli bir değeri başka bir değerle değiştirir.count(): Her sütundaki non-null (boş olmayan) veri sayısını verir.nunique(): Her sütundaki benzersiz (tekrar etmeyen) veri sayısını verir.sum(): Her sütundaki sayısal verilerin toplamını verir. Eğer sütunda sayısal veri yoksa o sütun atlanır.corr(): Sütunlar arasındaki korelasyon matrisini oluşturur. Korelasyon, iki değişken arasındaki ilişkinin gücünü ve yönünü ölçer. Değerler -1 ile 1 arasındadır. -1 mükemmel negatif korelasyonu, 1 mükemmel pozitif korelasyonu ve 0 korelasyon olmadığını gösterir.
calisan_verileri.count()
count(), sum(), mean(), min(), max(), std() ve corr() fonksiyonları hem Series hem de DataFrame veri yapıları için kullanılabilirken nunique(), value_counts() gibi fonksiyonlar ise yalnızca Series veri yapısı için kullanılabilirdir.
calisan_verileri.Team.value_counts() # hangi takımda kaç kişi var?
# Takımlara ait istatistikler
calisan_verileri.groupby('Team').mean()
calisan_verileri.groupby('Team').Team.count()
calisan_verileri.Team.unique() # Tekil verileri getirir.
Eksik veri işlemleri#
None ve NaN veri tipleri#
Python’da eksik verileri temsil etmek için genellikle iki ana veri tipi kullanılır: None ve NaN.
None, bir değişkenin değerinin bilinmediği veya tanımlanmadığı durumlarda kullanılır. Örneğin, bir fonksiyonun dönüş değerinin tanımsız olduğu durumlarda None kullanılır.
NaN (Not a Number) ise matematiksel işlemler sırasında ortaya çıkan veya eksik sayısal verileri temsil etmek için kullanılır. NaN, float veri tipi içinde kullanılır ve matematiksel işlemler sırasında oluşan sayısal hataları temsil eder.
Pandas kütüphanesi de eksik verileri temsil etmek için NaN değerini kullanır. NaN değeri, bir DataFrame veya Series içindeki belirli bir hücrenin değerinin eksik olduğunu belirtir. Pandas, NaN değerlerini otomatik olarak tespit eder ve bu değerleri işlem yaparken dikkate alır.
Eksik verilerin doğru şekilde yönetilmesi, veri analizi ve modelleme sırasında önemlidir. Pandas, eksik verileri ele almak için çeşitli yöntemler sunar, bunlar arasında eksik verileri silmek, eksik verileri belirli bir değer ile doldurmak veya eksik verileri interpolate etmek yer alır.
print(type(None)) # NoneType
print(type(np.nan)) # <class 'float'>
Yukarıdaki kodda görüldüğü gibi None ve NaN arasındaki fark, temsil ettikleri veri tiplerinden kaynaklanır.
None bir Python nesnesidir ve bir değişkenin değerinin bilinmediği veya tanımlanmadığı durumlarda kullanılır. None, herhangi bir veri tipine ait olmayan özel bir değerdir ve yalnızca Python programlama dilinde kullanılır.
NaN (Not a Number) ise float veri tipinde kullanılan bir değerdir. Matematiksel işlemler sırasında oluşan veya eksik sayısal verileri temsil etmek için kullanılır. NaN, sayısal bir değerin tanımsız veya hesaplanamaz olduğunu belirtir.
Yani, None bir nesne veya değişkenin tanımlanmadığı veya bilinmediği durumlarda kullanılırken, NaN sayısal değerlerde oluşan eksik veya tanımsız durumlar için kullanılır.
print(np.nan + 1) # nan
print(None + 1) # unsupported operand type(s) for +: 'NoneType' and 'int'
 Öncelikle, bir eksik veri serisi oluşturmak için `None` ve `NaN` değerlerini kullanabiliriz.
Öncelikle, bir eksik veri serisi oluşturmak için `None` ve `NaN` değerlerini kullanabiliriz.eksik_veri_serisi = np.array([None, np.nan, 1,2,3,"Merhaba"])
eksik_veri_df = pd.DataFrame(eksik_veri_serisi)
print(eksik_veri_df)
isnull(), isna(), notnull(), notna() fonksiyonları#
Bu seri, 2 tane eksik veri içermektedir. Bu eksik verileri tespit etmek için isnull() fonksiyonu kullanılabilir.
eksik_veri_df.isnull()
print(eksik_veri_df.isnull().sum().sum()) # toplam eksik veri sayısı 2
print(eksik_veri_df.notna().sum().sum()) # eksik olmayan veri sayısı 4
fillna()#
Eksik verileri doldurmak için, fillna() fonksiyonunu kullanabiliriz. Bu fonksiyon, belirli bir değerle eksik verileri doldurur. Örneğin, aşağıdaki örnekte eksik verileri 0 ve -999 ile dolduruyoruz:
print(eksik_veri_df.fillna(value=0))
print(eksik_veri_df.fillna(value=-999))
Başka bir seçenek olarak, ffill ve bfill yöntemlerini kullanarak eksik verileri önceki veya sonraki değerlerle doldurabiliriz.
seri_ffill = eksik_veri_df.fillna(method='ffill') # önceki değerle doldur
print(seri_ffill)
seri_bfill = eksik_veri_df.fillna(method='bfill') # sonraki değerle doldur
print(seri_bfill)
ffill yöntemi, eksik verileri önceki değerle doldururken, bfill yöntemi sonraki değerle doldurur.
Ayrıca, interpolate yöntemini kullanarak, eksik verileri verilerin aritmetik ortalaması veya doğrusal bir model kullanarak interpolate edebiliriz. Bu yöntemi kullanmadan önce serinin nümerik değerlerden oluştuğundan emin olmak gereklidir.
seri_interpolate = pd.Series([1, 2, np.nan, 4, np.nan, 6]).interpolate()
print(seri_interpolate)
Yukarıdaki örnekte, eksik verileri doğrusal bir model kullanarak interpolate ettik. Eksik veriler, verilerin aritmetik ortalaması veya başka bir yöntemle de doldurulabilir.
dropna() fonksiyonu, eksik verileri içeren satırları veya sütunları veri kümesinden kaldırmak için kullanılır. Bu fonksiyon, NaN değerlerini içeren satırları veya sütunları veri kümesinden çıkararak yeni bir veri kümesi oluşturur.
İlk olarak, bir örnek veri kümesi oluşturalım:
dropna()#
dropna() fonksiyonu, eksik verileri içeren satırları veya sütunları veri kümesinden kaldırmak için kullanılır. Bu fonksiyon, NaN değerlerini içeren satırları veya sütunları veri kümesinden çıkararak yeni bir veri kümesi oluşturur.
İlk olarak, bir örnek veri kümesi oluşturalım:
df = pd.DataFrame({'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]})
print(df)
Bu veri kümesinde, NaN değerleri içeren satırlar ve sütunlar var. Bu veri kümesinden dropna() fonksiyonunu kullanarak, NaN değerlerini içeren satırları kaldırabiliriz:
df_without_nulls = df.dropna()
print(df_without_nulls)
dropna() fonksiyonu, varsayılan olarak herhangi bir NaN değeri içeren satırı kaldırır ve yeni bir veri kümesi oluşturur. dropna() fonksiyonuna axis parametresi ekleyerek, NaN değerleri içeren sütunları kaldırabiliriz:
df_without_nulls_col = df.dropna(axis=1)
print(df_without_nulls_col)
Bu örnekte, axis=1 parametresi ile sütunları kaldırdık ve sadece C sütunu kaldı.
dropna() fonksiyonu, how parametresi ile daha spesifik davranışlar gösterir. Varsayılan olarak how='any' olarak ayarlanmıştır, yani herhangi bir eksik değer içeren satırlar veya sütunlar silinir. Ancak, how='all' olarak ayarlandığında, tüm değerleri eksik olan satırlar veya sütunlar silinir. Örneğin:
df_all_null = pd.DataFrame({'A': [np.nan, np.nan, np.nan],
'B': [np.nan, np.nan, np.nan],
'C': [np.nan, np.nan, np.nan]})
print(df_all_null)
Bu örnekte, tüm satırlar veya sütunlar NaN olduğu için, dropna() fonksiyonu tüm verileri kaldırdı ve boş bir DataFrame döndürdü.
Ayrıca, dropna() fonksiyonu thresh parametresi ile belirtilen eşik değerinden daha az sayıda geçerli (yani, eksik olmayan) değere sahip olan satırlar veya sütunlar silinir. Örneğin:
df_thresh = pd.DataFrame({'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, np.nan, np.nan]})
print(df_thresh)
Bu veri kümesinde, en az 2 geçerli değere sahip satırlar veya sütunlar korunacak:
df_thresh_dropped = df_thresh.dropna(thresh=2)
print(df_thresh_dropped)
Bu örnekte, sadece 2 veya daha fazla geçerli değere sahip olan satırlar ve sütunlar korundu. thresh parametresi, verilerin çeşitli yönlerde temizlenmesine yardımcı olabilir, özellikle büyük veri kümelerinde, verilerin sadece bir kısmı eksikse.
Aykırı veri analizi#
Pandas, aykırı verilerin tespiti ve analizi için kullanılabilen bir dizi fonksiyona sahiptir. Aykırı veriler, genellikle diğer verilerden önemli ölçüde farklı olan ve istatistiksel analizlerde yanıltıcı sonuçlara neden olabilen verilerdir.
Pandas’da aykırı verileri tespit etmek için kullanabileceğiniz birkaç yöntem vardır. Bunlar arasında:
describe()yöntemi: Bu yöntem, veri setinin istatistiklerini hesaplar ve aykırı değerlerin olup olmadığını gösterir.describe()yöntemi, veri setindeki en küçük ve en büyük değerleri, ortalamayı, standart sapmayı ve çeyrekliklerin değerlerini gösterir.boxplot()yöntemi: Bu yöntem, kutu grafiği olarak da bilinir ve veri setindeki aykırı değerleri görselleştirir. Kutu grafiği, veri setinin dağılımını gösterir ve aykırı değerlerin kutunun dışında kalan noktalar olarak belirtilir.quantile()yöntemi: Bu yöntem, belirli bir yüzdelik aralığında yer alan değerleri hesaplar. Bu yöntem kullanılarak, belirli bir yüzdelik aralığına girmeyen değerler aykırı olarak kabul edilebilir.isolation forestyöntemi: Bu yöntem, veri setindeki aykırı değerleri tespit etmek için bir makine öğrenmesi algoritmasıdır. Bu yöntem, veri setindeki aykırı değerleri gruplamak için ağaç yapısı kullanır.
Bunlar, pandas kütüphanesi ile aykırı veri analizi için kullanılabilecek yöntemlerden sadece birkaçıdır. Bu yöntemler, veri setindeki aykırı değerleri tespit etmek ve işlemek için kullanılabilir.
IQR yöntemi#
IQR (Interquartile Range) yöntemi, aykırı değerleri tanımlamak için kullanılan bir istatistiksel yöntemdir. Bu yöntem, veri dağılımındaki çeyrekliklerin aralığını kullanarak bir alt ve üst sınır belirler ve bu sınırların dışındaki değerleri aykırı olarak tanımlar.
IQR, bir veri kümesindeki değerlerin ortalamasının yerine veri dağılımının merkezi eğilim ölçüsü olarak kullanılır. Veri kümesindeki değerlerin çoğu IQR içinde kaldığı için, IQR yöntemi aykırı değerleri belirlemek için daha güvenilirdir. IQR, verilerin ortalamasına karşı daha dayanıklıdır çünkü sadece veri kümesinin ortasındaki değerlerin aralığını kullanır.
IQR yöntemi kullanarak aykırı değerleri belirlemek için, verilerin 1. ve 3. çeyrekliklerinin aralığı (yani IQR) hesaplanır. Ardından, alt sınır Q1 - 1.5 x IQR ve üst sınır Q3 + 1.5 x IQR şeklinde hesaplanır. Bu sınırların dışındaki herhangi bir değer aykırı olarak kabul edilir.
Örneğin, bir veri kümesinde Q1 = 20 ve Q3 = 50 olsun. Bu durumda, IQR = Q3 - Q1 = 50 - 20 = 30 olacaktır. Alt sınır, 20 - 1.5 x 30 = -5, üst sınır ise 50 + 1.5 x 30 = 95 olacaktır. Veri kümesindeki herhangi bir değer -5’ten küçük veya 95’ten büyükse aykırı olarak kabul edilecektir.
Aşağıdaki örnekte titanic veri seti üzerinde bir aykırı veri analizi gösterilmiştir.
veri_seti = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
veri_seti.head()
veri_seti.isnull().sum()
# veri setinin doldurulması
doldurulmus_veri = veri_seti.fillna(method="bfill").fillna(method="ffill")
Aşağıdaki komut, “Age” sütununun istatistiksel özetini oluşturur. İstatistiksel özet, sütunun minimum ve maksimum değerleri, ortalama, standart sapma, medyan ve çeyreklikler gibi önemli özelliklerini içerir. “describe()” fonksiyonu, veri çerçevesindeki sayısal sütunlar için bu tür istatistiksel özetler oluşturmak için sıklıkla kullanılan bir yöntemdir.
doldurulmus_veri.Age.describe()
Aşağıdaki komut, “Age” adlı bir değişkenin kutu grafiğini çizmek için Pandas kütüphanesinin “plot” fonksiyonunu kullanır.
Bu komut, bir veri çerçevesindeki “Age” sütununu seçerek, sütundaki sayısal verilerin çeyrekler arası mesafeleri, minimum ve maksimum değerleri, olası aykırı değerleri vb. görselleştiren bir kutu grafiği çizer. Bu grafiği kullanarak, veri setindeki “Age” sütunundaki dağılımı görsel olarak anlayabiliriz.
doldurulmus_veri.Age.plot.box()
Q1 = doldurulmus_veri.Age.quantile(q=0.25)
Q3 = doldurulmus_veri.Age.quantile(q=0.75)
IQR = Q3 - Q1
print("Q1: {}, Q3: {}, IQR: {}".format(Q1, Q3, IQR)) # Q1: 21.0, Q3: 39.0, IQR: 18.0
alt_sinir = Q1-1.5*IQR
ust_sinir = Q3 + 1.5*IQR
alt_sinir, ust_sinir # (-6.0, 66.0)
# alt sınırın altında veri var mı?
doldurulmus_veri.Age[doldurulmus_veri.Age < alt_sinir]
# üst sınırın üzerinde veri var mı?
doldurulmus_veri.Age[doldurulmus_veri.Age>ust_sinir]
# alt sınır ve üst sınırı aşan verileri traşladık
doldurulmus_veri.Age[doldurulmus_veri.Age > ust_sinir] = ust_sinir
doldurulmus_veri.Age[doldurulmus_veri.Age < alt_sinir] = alt_sinir
# yeniden kontrol edildiğinde
doldurulmus_veri.Age.plot.box()
Z-Skoru yöntemi#
Z-skoru yöntemi, verilerin ortalama ve standart sapma değerlerini kullanarak aykırı değerleri belirlemek için kullanılan bir yöntemdir. Bu yöntemde, verilerin standart sapma değerlerine göre ne kadar uzağa olduklarına göre bir skor verilir. Skorların dağılımı normal dağılıma göre ayarlanır ve genellikle 3’ün üzerinde veya altında kalan skorlar aykırı değer olarak kabul edilir.
Z-skoru hesaplamak için, her bir veri noktasının ortalama değerden uzaklığının standart sapmaya bölünmesi gerekir. Formül aşağıdaki gibidir:
Z = (x - mean) / std
Burada:
x, herhangi bir veri noktası
mean, veri setinin ortalaması
std, veri setinin standart sapması
Örneğin, bir veri setinde ortalama değer 50 ve standart sapma 10 ise, bir veri noktası 70 olsun. Z-skoru aşağıdaki şekilde hesaplanabilir:
Z = (70 - 50) / 10 = 2
Bu veri noktası, veri setinin normal dağılımına göre 2 standart sapma yukarıdadır. Eğer bu değer 3’ten büyükse veya -3’ten küçükse, bu veri noktası aykırı değer olarak kabul edilir.
Pandas kütüphanesi ile Z-skoru yöntemi kullanılarak aykırı değerleri bulmak için, “zscore” fonksiyonu kullanılabilir. Bu fonksiyon, belirli bir sütundaki her bir veri noktasının Z-skorunu hesaplar ve bunları yeni bir sütuna ekler. Ardından, belirli bir eşik değerine göre aykırı değerleri seçmek için bu sütunu filtrelemek mümkündür. Örneğin:
# Verileri yükle
df = doldurulmus_veri
# 'degerler' sütunundaki her bir veri noktasının Z-skorunu hesapla
df['z_score'] = (df['Age'] - df['Age'].mean()) / df['Age'].std()
# Z-skoru eşiği 3 olan aykırı değerleri seç
outliers = df.loc[df['z_score'].abs() > 3, :]
outliers
Veri dönüşüm işlemleri#
Pandas kütüphanesi, verileri manipüle etmek için birçok işlevsellik sunar. Bu işlevsellikler arasında veri dönüşümleri, normalizasyon, standardizasyon ve kesikli hale getirme gibi işlemler de bulunur.
Veri dönüşümleri: Veri dönüşümleri, verilerin farklı birimler veya formatlarla sunulduğu durumlarda kullanışlıdır. Pandas’ta veri dönüşümleri, “apply” ve “map” fonksiyonları gibi farklı yöntemlerle gerçekleştirilebilir.
Normalizasyon: Normalizasyon, verilerin arasındaki değerleri sınırlandırarak verilerin dağılımını düzenler. Bu işlem sayesinde farklı birimlerdeki veriler aynı ölçekte karşılaştırılabilir hale gelir. Normalizasyon için genellikle Min-Max Normalizasyonu kullanılır.
Standardizasyon: Standardizasyon, verilerin arasındaki standart sapmaları kullanarak verilerin dağılımını düzenler. Bu işlem sayesinde farklı birimlerdeki verilerin dağılımları daha anlamlı hale gelir. Standardizasyon için genellikle Z-skoru yöntemi kullanılır.
Kesikli hale getirme: Kesikli hale getirme, sürekli sayısal verileri belirli aralıklarla kesikli hale getirerek verilerin anlamlı hale gelmesini sağlar. Bu işlem, özellikle makine öğrenimi modellerinde kategorik değişkenlerle birlikte kullanılmak üzere faydalıdır.
Örnek olarak, veri setindeki bir sütunu normalizasyon, standardizasyon veya kesikli hale getirme işlemlerinden biri ile işleyebilirsiniz. Örneğin, “Age” sütununu 0 ile 1 arasındaki değerlere normalizasyon yaparak işleyebilirsiniz:
Normalizasyon#
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['Age_Normalized'] = scaler.fit_transform(df[['Age']])
Bu kodda, “Age” sütununun değerleri Min-Max Normalizasyon yöntemi ile 0 ile 1 arasındaki değerlere dönüştürülüp “Age_Normalized” adlı yeni bir sütunda saklanır.
Ya da benzer işlem kendi yazacağımız denklem üzerinden de gerçekleştirilebilir. Aşağıdaki kodlar bu amacı yerine getirmektedir.
yas = doldurulmus_veri.Age
normalize_edilmis = (yas - yas.min())/(yas.max()-yas.min())
normalize_edilmis.describe()
Standardizasyon#
Tablodaki ‘Salary’ sütununu standardize etmek için örnek bir pandas kodu aşağıdaki gibi olabilir:
from sklearn.preprocessing import StandardScaler
# Örnek bir veri seti
data = {'Name': ['Ali', 'Veli', 'Ahmet', 'Mehmet'],
'Age': [27, 31, 25, 29],
'Salary': [5000, 7000, 4500, 6000]}
# Verileri bir pandas DataFrame nesnesine dönüştürme
df = pd.DataFrame(data)
# Verileri standardize etme
scaler = StandardScaler()
df['Standardized_Salary'] = scaler.fit_transform(df[['Salary']])
# Sonuçları yazdırma
print(df)
Bu kodda, StandardScaler fonksiyonu ile Salary sütunu standart normal dağılım (ortalama 0 ve standart sapma 1) haline getiriliyor. Bu işlem, tüm veri setinin aynı ölçekte olmasını sağlamak için yapılır ve makine öğrenmesi modelleri gibi bazı analizlerde gereklidir. Yeni standartlaştırılmış sütun, Standardized_Salary olarak adlandırılır ve DataFrame’e eklenir.
Kesikli hale getirme#
Kesikli hale getirme (discretization), bir sürekli değişkenin belirli aralıklara ayrılması işlemidir. Bu işlem sayesinde veriler daha kolay yorumlanabilir ve anlaşılabilir hale gelir.
Pandas kütüphanesi ile kesikli hale getirme işlemi cut() fonksiyonu ile yapılabilir. Bu fonksiyon, bir aralık serisini kesikli kategorik bir değişkene dönüştürür. Örneğin, bir veri setindeki yaş değişkenini belirli aralıklara bölerek yaş kategorileri elde etmek için kullanılabilir.
Aşağıda örnek bir kesikli hale getirme işlemi bulunmaktadır:
# Örnek veri seti
veri = pd.DataFrame({'yaş': [25, 36, 42, 29, 51, 46, 39, 33, 28, 24]})
# Yaş aralıklarını belirleme
araliklar = [0, 30, 40, 60]
# Yaş değişkenini kesikli hale getirme
veri['yaş_kategorisi'] = pd.cut(veri['yaş'], araliklar)
print(veri)
Bu kod örneği, yaş değişkenindeki her bir değeri belirtilen aralıklara göre kesikli hale getirir ve yeni bir yaş_kategorisi değişkeni oluşturur. Çıktı aşağıdaki gibi olacaktır:
yaş yaş_kategorisi
0 25 (0, 30]
1 36 (30, 40]
2 42 (40, 60]
3 29 (0, 30]
4 51 (40, 60]
5 46 (40, 60]
6 39 (30, 40]
7 33 (30, 40]
8 28 (0, 30]
9 24 (0, 30]
Görüldüğü gibi, her bir yaş değeri, belirlenen aralıklara göre bir kategoriye atanmıştır. Bu şekilde, yaş değişkeni daha anlamlı ve yorumlanabilir bir hale getirilmiştir.
yas_kategorileri = ["cocuk", "genc", "yasli"]
pd.cut(x=veri['yaş'], bins=araliklar, labels=yas_kategorileri)
One-hot encoding#
One-Hot Encoding, kategorik değişkenlerin (categorical variables) makine öğrenmesi algoritmalarında kullanılabilmesi için sayısal veriye dönüştürülmesi işlemidir. Bu işlem, her kategorik değişkenin ayrı bir özellik olarak ele alındığı ve bu özelliklerin sadece 0 veya 1 değerleri alabildiği yeni bir veri kümesi oluşturur. Bu yöntem, sınıflandırma algoritmalarının daha doğru sonuçlar vermesine yardımcı olur.
Örnek olarak, bir “renk” değişkeni düşünelim. Bu değişken “kırmızı”, “yeşil” ve “mavi” gibi 3 farklı kategorik değer alabilsin. One-Hot Encoding ile bu değişken, “renk_kırmızı”, “renk_yeşil” ve “renk_mavi” olmak üzere 3 farklı özellik haline dönüştürülür. Her bir özellik, orijinal “renk” değişkeninin o değerine sahipse 1, diğer durumlarda 0 değerini alır.
Pandas kütüphanesi, One-Hot Encoding işlemi için get_dummies() fonksiyonunu sağlar. Bu fonksiyon, kategorik değişkenleri otomatik olarak bulur ve yeni özellikler haline dönüştürür. Örnek kullanım aşağıdaki gibidir:
# Örnek veri seti
data = {'renk': ['kırmızı', 'mavi', 'yeşil', 'mavi', 'kırmızı']}
# Veri setini DataFrame'e dönüştürme
df = pd.DataFrame(data)
# One-Hot Encoding işlemi
one_hot_encoded = pd.get_dummies(df['renk'])
# Yeni özellikleri DataFrame'e ekleme
df = pd.concat([df, one_hot_encoded], axis=1)
# Sonuçları görüntüleme
print(df)
Benzer işlem titanic veri setine de yapılabilir.
veri_seti.Embarked.head()
veri_seti.Embarked.value_counts()
# Kukla değişken - one-hot encoding
pd.get_dummies(veri_seti.Embarked).head()
Formül Uygulama#
Pandas kütüphanesi, map() ve apply() gibi fonksiyonlar aracılığıyla veri işleme işlevselliği sağlar.
map() fonksiyonu, bir pandas Serisi’ndeki tüm öğeleri değiştirmek için kullanılır. Bu işlev, bir sözlük, işlev veya Seri nesnesi alabilir ve Seri öğelerini değiştirmek için bu nesneleri kullanır. Örneğin aşağıdaki kod, Salary Serisi’deki tüm öğelere 200.000 artırarak ve sonucu ekrana yazdıracaktır:
calisan_verileri.Salary.map(lambda x: x+200000) # Salary lere toplu artış
apply() fonksiyonu ise, bir DataFrame’in bir sütununda veya satırında işlevleri uygulamak için kullanılır. apply() fonksiyonu, map() fonksiyonuna benzer şekilde işlevlerin uygulanmasında kullanılır ancak, DataFrame veri yapısında uygulanır. Aşağıdaki kod, istenilen DataFrame sütununda bir yazılan fonksiyonun işlemini yapacak ve sonucu ekrana yazdıracaktır.
def fonksiyon_ismi(x):
return x + 200000
calisan_verileri.Salary.apply(fonksiyon_ismi)
def sayi_formatla(x):
return f"{x:.1f}"
calisan_verileri["Bonus %"].apply(sayi_formatla)
Aşağıdaki örneklerde ise pandas veri çerçevelerine yeni bir sütun eklemek için işlemler gösterilmiştir. Yeni bir sütun oluşturmak için iki aşama gereklidir:
Yeni bir sütun oluşturmak ve ona bir ad vermek
Yeni sütunun her bir hücresine değer atamak
Bunun için [] operatörü ve atama işlemi = kullanılır. Örneğin, aşağıdaki kod bir veri çerçevesine yeni bir sütun ekleyecek ve içerisine sabit bir “herhangi bir değer” yazdıracaktır:
calisan_verileri['yeni_sutun'] = 'herhangi bir değer'
calisan_verileri.head()
calisan_verileri['Yeni Sütun'] = np.random.randint(
low=10, high=20,
size=calisan_verileri.shape[0]) # yeni sütun rassal verilerden oluşturuldu
Örneğin, aşağıdaki kod “Yeni Sütun” sütunundaki her bir değeri 2 ile çarpacaktır:
calisan_verileri['Yeni Sütun'] = calisan_verileri['Yeni Sütun'] * 2
Burada, calisan_verileri[‘Yeni Sütun’] * 2 ifadesi, Yeni Sütun sütunundaki her bir değeri 2 ile çarpar ve sonucunu tekrar calisan_verileri[‘Yeni Sütun’] sütununa atar.
Nüfusu yüksek olan şehirleri bir sütunda tutmak istersek şu şekilde bir kod yazabiliriz.
sehirler['nufusu_yuksek'] = sehirler.nufuslar > 1000000
sort_values() fonksiyonu, bir veri çerçevesindeki sütunlara göre sıralama yapmaya yarayan bir fonksiyondur. Bu fonksiyon, veri çerçevesindeki belirli bir sütuna göre verileri küçükten büyüğe veya büyükten küçüğe doğru sıralama yapar.
calisan_verileri.sort_values(by=['Salary', 'Bonus %'], ascending=False)
rename() fonksiyonu, bir veya daha fazla ekseni, satır veya sütun etiketlerini yeniden adlandırmak için kullanılır.
Fonksiyonun genel kullanımı aşağıdaki gibidir:
calisan_verileri.rename(columns={
'Bonus %': 'Bonus__%',
'Team': 'Teams'
}).head()
Veri Seçme ve Verilere Ulaşma#
Dosya yüklendikten ve veri setini anladıktan sonra, bazı verilere erişmek isteyebiliriz. Pandas, veri seçme, indeksleme ve filtreleme işlemleri için birçok farklı yöntem sunar. Bu yöntemlerin en sık kullanılanları şunlardır:
İndeksleme operatörü ([]): Bu operatör ile belirli bir sütun ya da satır seçilebilir. Örneğin, veri çerçevesindeki ‘Name’ sütununu seçmek için df[‘Name’] kullanılır..loc[]: Bu metot ile satır ve sütun isimleri veya konumlarına göre seçim yapılabilir. Örneğin, veri çerçevesindeki 3. satırı ve ‘Age’ sütununu seçmek için df.loc[3, ‘Age’] kullanılır..iloc[]: Bu metot ile satır ve sütun konumlarına göre seçim yapılabilir. Örneğin, veri çerçevesindeki 2. satırı ve 3. sütunu seçmek için df.iloc[1, 2] kullanılır.Boolean indeksleme: Bu metot ile belirli koşulları sağlayan satırlar seçilebilir. Örneğin, veri çerçevesindeki yaş değeri 30’dan büyük olan satırların seçimi için df[df[‘Age’] > 30] kullanılır..query(): Bu metot ile belirli koşullara göre satırlar seçilebilir. Örneğin, veri çerçevesindeki yaş değeri 30’dan büyük olan satırların seçimi için df.query(‘Age > 30’) kullanılır..isin(): Bu metot ile belirli bir değere sahip olan satırlar seçilebilir. Örneğin, veri çerçevesindeki ‘Gender’ sütununda ‘Female’ değerine sahip olan satırların seçimi için df[df[‘Gender’].isin([‘Female’])] kullanılır..between(): Bu metot ile belirli bir aralıkta olan değerlere sahip olan satırlar seçilebilir. Örneğin, veri çerçevesindeki yaş değeri 20 ile 30 arasında olan satırların seçimi için df[df[‘Age’].between(20, 30)] kullanılır.
Bu yöntemlerin her biri, farklı durumlar için kullanışlıdır ve veri çerçevelerinde veri seçimi, indeksleme ve filtreleme işlemlerinin kolay ve esnek bir şekilde yapılmasına olanak tanır.
print(calisan_verileri["Team"]) # sadece Team sütununu getirir.
calisan_verileri[["Team", "Bonus %"]] # iki sütunu birlikte getirir
Ayrıca, belli bir koşulu sağlayan satırlara erişmek için de loc[] fonksiyonunu kullanabiliriz. Bu fonksiyon, koşulu sağlayan satırları getirir.
iloc#
iloc fonksiyonu, verilerin indeks numaralarına göre erişim sağlar. İndeks numarası, satırın konumunu belirtir ve sütun adı belirtilmezse tüm sütunlar döndürülür. Örneğin, aşağıdaki DataFrame nesnesinde, “isim”, “yaş” ve “şehir” sütunlarındaki 1. indeksteki satırlara erişmek istediğimizi varsayalım:
data = {
'isim': ['Ahmet', 'Mehmet', 'Ali', 'Ayşe'],
'yaş': [28, 22, 30, 25],
'şehir': ['İstanbul', 'Ankara', 'İzmir', 'Bursa']
}
df = pd.DataFrame(data)
# İlk satırlara erişim
print(df.iloc[1]) # Sadece bir satır döndürür
print(df.iloc[[1]]) # Bir DataFrame nesnesi döndürür
print(df.iloc[[1, 2]]) # İki satırı içeren bir DataFrame nesnesi döndürür
# İlk satırlara ve belirli sütunlara erişim
print(df.iloc[1, 0]) # Sadece bir değer döndürür
print(df.iloc[
[1, 2],
0:2]) # İki satırı ve ilk iki sütunu içeren bir DataFrame nesnesi döndürür
loc#
loc fonksiyonu, satırların etiket veya koşullara göre erişim sağlar. Etiket veya koşul belirtilmezse, tüm satırlar döndürülür. Örneğin, aşağıdaki DataFrame nesnesinde, “isim”, “yaş” ve “şehir” sütunlarındaki “Mehmet” ve “Ali” isimli satırlara erişmek istediğimizi varsayalım:
data = {
'isim': ['Ahmet', 'Mehmet', 'Ali', 'Ayşe'],
'yaş': [28, 22, 30, 25],
'şehir': ['İstanbul', 'Ankara', 'İzmir', 'Bursa']
}
df = pd.DataFrame(data)
# Etiket veya koşullara göre erişim
print(df.loc[df['isim'] == 'Mehmet']) # Bir DataFrame nesnesi döndürür
print(df.loc[df['isim'].isin(
['Mehmet', 'Ali'])]) # İki satırı içeren bir DataFrame nesnesi döndürür
# Etiket veya koşullara göre erişim ve belirli sütunlar
print(df.loc[df['isim'] == 'Mehmet', 'yaş']) # Sadece bir değer döndürür
print(df.loc[df['isim'].isin(['Mehmet', 'Ali']), ['yaş', 'şehir']]) #
df[sütun]: DataFrame’den tek bir sütun veya sütun dizisi seçin; özel durum kolaylıkları: Boolean array (satırları filtreleme), slice (satırları dilimleme) veya Boolean DataFrame (bir kriterle değerleri ayarlama)
df.loc[satırlar]: Etiketleme ile DataFrame’den tek bir satır veya alt küme seçin
df.loc[:, sütunlar]: Etiketleme ile tek bir sütun veya sütun alt kümesini seçin
df.loc[satırlar, sütunlar]: Hem satır(lar) hem de sütun(lar) etiketle seçin
df.iloc[satırlar]: DataFrame’den tek bir satır veya satır alt kümesini konumla seçin
df.iloc[:, sütunlar]: Tamsayı pozisyonu ile tek bir sütun veya sütun alt kümesini seçin
df.iloc[satırlar, sütunlar]: Hem satır(lar) hem de sütun(lar) tamsayı pozisyonu ile seçin
df.at[satır, sütun]: Bir satır ve sütun etiketiyle tek bir skaler değeri seçin
df.iat[satır, sütun]: Bir satır ve sütun pozisyonu (tamsayılar) ile tek bir skaler değeri seçin
Sonuç#
Bu bölümde, pandas’ın önemli bir araç olmasını sağlayan temel özelliklerini inceledik. Uygulamalı örneklerle kütüphanenin yeteneklerini keşfettik. Seriler ve Veri Çerçeveleri gibi veri nesneleri, int64, float ve object gibi veri tipleri ve veri dönüştürme işlemleri için farklı yöntemler hakkında bilgi sahibi olduk. Daha sonra, veri seçimi ve indeksleme gibi farklı yöntemlerle veri manipülasyonu gerçekleştirdik.